Scientific Truths are Not Self Evident: Science, Perception, and Identity in America Since the 1960s
An Introduction
Across contemporary American culture, science has been an oftentimes divisive and emotional issue. With new technologies like CRISPR and artificial intelligence (AI), it seems that the perception of scientific issues, particularly those relating to our everyday lives [6], is becoming more and more polarized. Some argue that technology and the science behind it are tools for cultural convergence [15], but in the era of Trump, I have found that the way we think about science has changed dramatically, and it has become a political tool for shaping culture. In this project, I am asking the following questions: what are the factors that determine our perceptions of science, how have those factors evolved over the last half century, and why?
My Motivation
As a student of computer science, I find AI to be a compelling topic; one in which mathematical optimization and large datasets are used to astonishing results. Having studied AI on my own, and then turning to look at its portrayal in the media, it often surprised me how incorrect those portrayals were, and how they were so rooted in fear. Here, I seek to provide some answers.
Some More Background
In order to evaluate the evolution of societal perceptions, I looked back to the 1960s. I originally thought of the space race, a time of pride in our scientific achievements. However, I also had to be concerned about the fear that was deeply rooted in the missile crisis and cold war. Moreover, various cultural societies had reason to evaluate these events differently. For example, it can be argued that black Americans were proud of NASA’s achievements, but were frustrated by their lack of involvement and their untapped potential, which was stifled by racial discrimination [16]. In this, I came to realize that perhaps my own perceptions as a white male were in part to blame, as I hadn’t considered the black perspective on the space race. With this, I set out to find data to answer these important questions.
Methodology
Deciding on data
I used two different types of primary data in my project. I first decided to find a contemporary representation of culture and how science is reflected in it. This idea led me to consider Twitter, perhaps the preeminent mode of networking in our society today. I think social media is a good proxy for what contemporary culture represents; it evolves with our beliefs, politics, and identities. Consequently, I found two relevant Twitter datasets: one about #ClimateMarch, and one about #MarchForScience [13, 14].
The other major type of primary data is that which is representative of the 1960s. For this, I looked for a corpus containing a broad spectrum of media (articles, books, newspapers, etc.). Print media was a much larger cultural influencer in the pre-internet era, so I think that using such a type of corpus is justified in trying to understand cultural perceptions. Neatly enough, I found the Brown corpus, a corpus compiled by researchers of the university with the same name, containing exactly that kind of media [3].
Collecting data
Collecting the Twitter data required applying for a developer account and then downloading the tweets one by one. This restriction is due to new privacy and copyright restrictions, probably in part to recent scandals (looking at you Facebook). I used a tool called twarc (https://github.com/DocNow/twarc) to download the tweets. The Brown corpus is widely available, and I got it from a Natural Language Processing (NLP) tool called NLTK, which has various corpora ready for download.
Cleaning the data
Cleaning the data involved a multi-step process. For the Twitter data, I removed all ‘RT’ strings, hashtags, URLs, and handles. I also removed the majority of emojis (sparing a few; it turns out removing emojis is a whole problem in its own which I will spare you the details). I stripped that information because it doesn’t provide much, if any, semantic value to my answering my research question.
The Brown corpus was much simpler. So simple in fact, that I didn’t need to clean it at all. I will note here that removing stopwords, common words like ‘the’, ‘and’, ‘a’, is not necessary for my methodologies.
I did also create CSV files in which each sentence/tweet was delimited on its own line, which made some of the analysis possible.
word2vec and Embedding Projector
Word2vec is an algorithm for producing word embeddings. In essence, this means that it is an algorithm that relies on predicting the contextual words most likely for a given word. To do this, the algorithm is given a set of training data on which it bases its contexts on. This idea is based on the distributional hypothesis, which says that words near each (in the same context) share meaning. In the process, the algorithm vectorizes words and learns embeddings. That is to say, it turns words into numbers that have meaning in relation to other ‘numberified’ words. For example, two words that are closely related should have similar numbers, or in technical terms, be close in the vector space. I used a library called genism to implement word2vec [12].
With these word embeddings produced by word2vec, I looked at different ways of analyzing them. One particularly useful tool is the embedding projector, developed by Google’s TensorFlow team [1]. It allows you to display your embeddings in 2D or 3D, and map vector relations. You can see examples of it in the results section.
KMeans Clustering
KMeans clustering is a technique for associating vectors into different groups, or ‘clusters’. It works by iteratively taking the distance from certain randomly initialized points (centroids) and associating each vector to the closest centroid, and then updating each centroid so it is at the mean of all the vectors assigned to it. This process repeats until a sort of equilibrium is reached. Clustering lets us see how different words form communities together.
Similarity Querying and Network Analysis with Gephi
An even more compelling way to look at word communities is by doing network analysis and visualization. I first started by taking a set of words that I found interesting to my topic (‘science’, ‘fear’, ‘justice’, etc.) and looking at which words were similar to them in the vector space produced by word2vec. I then converted these similarities into a graph representation and visualized the results with an open source tool called Gephi.
Results
Culture, Identity, and Politics through Network Analysis

Climate Graph
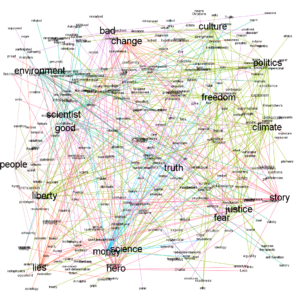
Brown Graph

March for Science Graph
From this graphical representation of science and different cultural ideas, we can see some patterns emerge. Note that the color of each edge indicates its community. Community selection was done by the modularity assignment algorithm in Gephi.
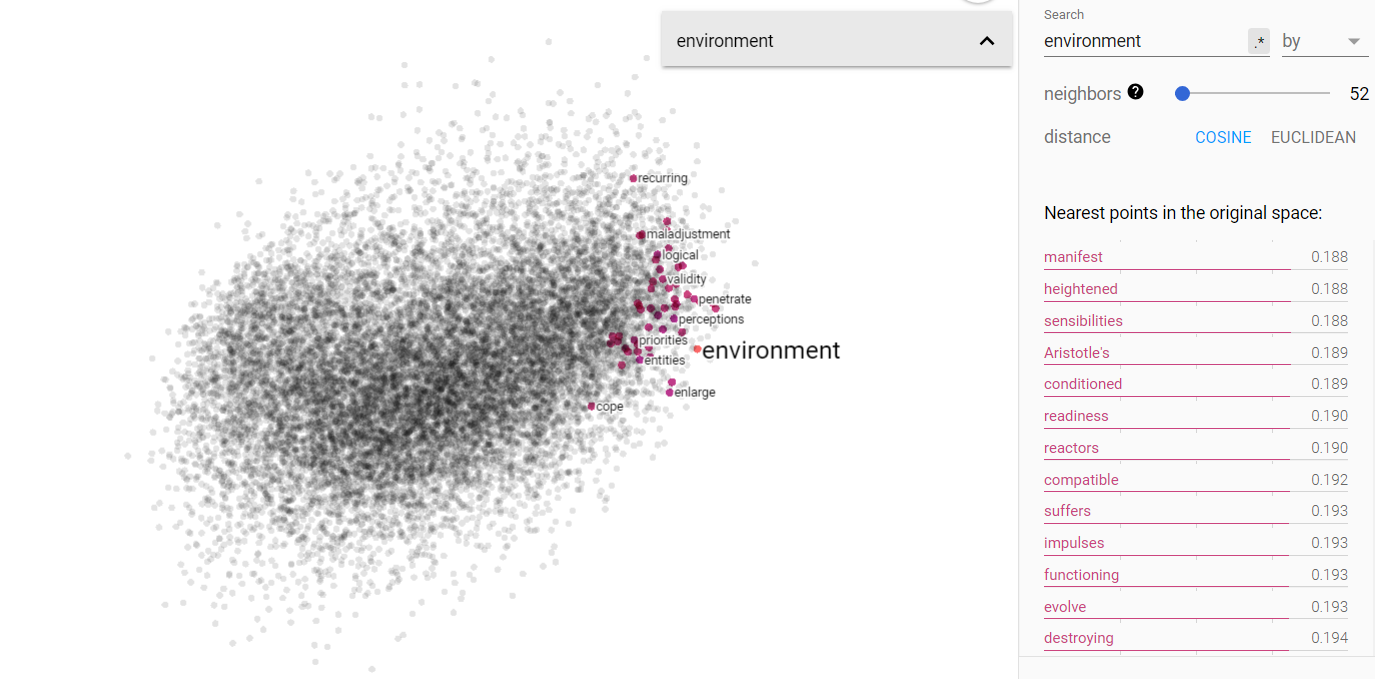
First, the Brown corpus indicates a strong connection between ideas of freedom, culture, and politics, and, surprisingly, science. To me, this indicates that science was treated as a powerful concept of national identity, on the same scale as culture itself, and important patriotic values like freedom. We can also see another interesting community in money, environment, and scientist. Perhaps this is indicative of the beginnings of the green movements.
However, the climate and march for science corpora tell a different story altogether. We can see that the green movement hasn’t continued to take shape, but instead climate has come to be associated with people, politics, and lies. The divergence in scientific belief regarding climate is further corroborated by Jones [8].
I also noted that politics and culture seem to have special importance in all three graphs. But, I think we already know to some extent that politics and culture are shaping factors in our lives and perceptions; instead I tried to hone in how they influence us. So, instead, I look more towards ideas of stories, truths, and narratives, as well as the influence of money, because the graphs above also give some indication that people, and thus the narratives surrounding them, are influential. And of course, we all know that money can drive narratives. To back this up, research has shown that how you say something can be even more important than what you say, even when you are talking about science [4, 8].
Narratives, Truths, and Money through Word Embeddings
Brown
First, I want to analyze the Brown corpus embeddings to get an idea of how these ideas of narratives and money played a role in our cultural perceptions in the past.
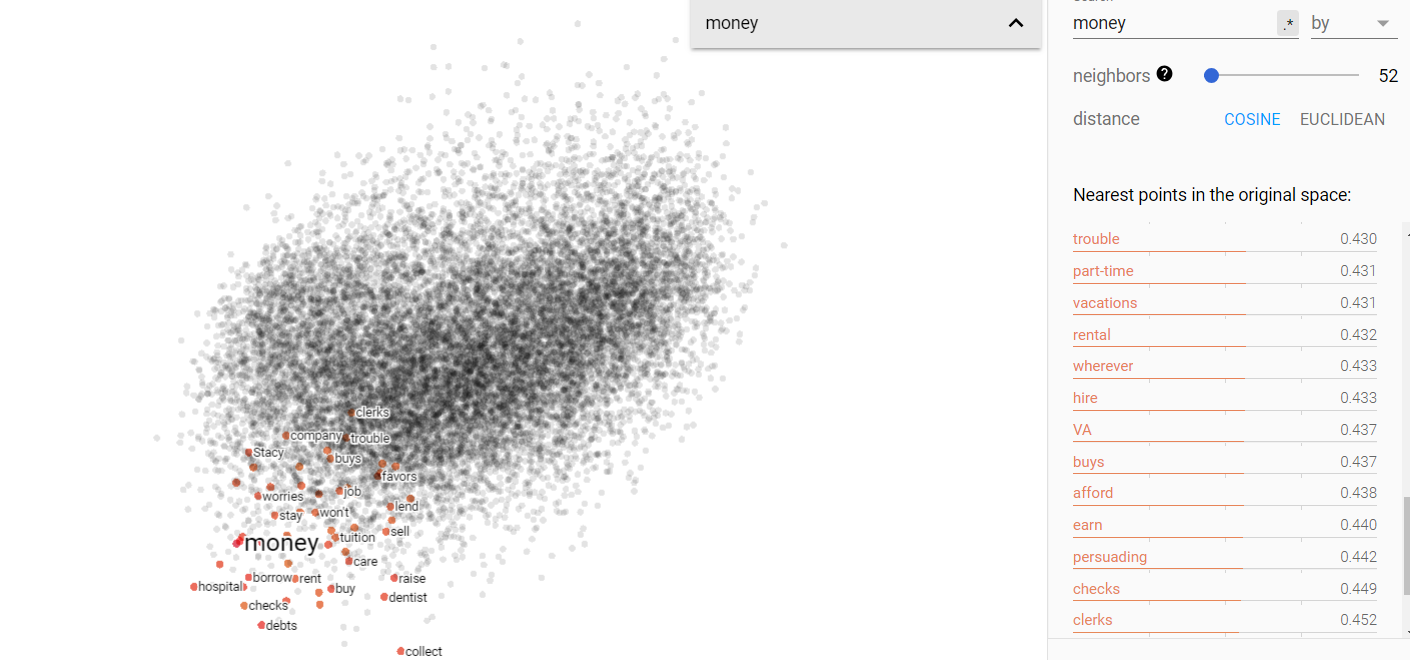
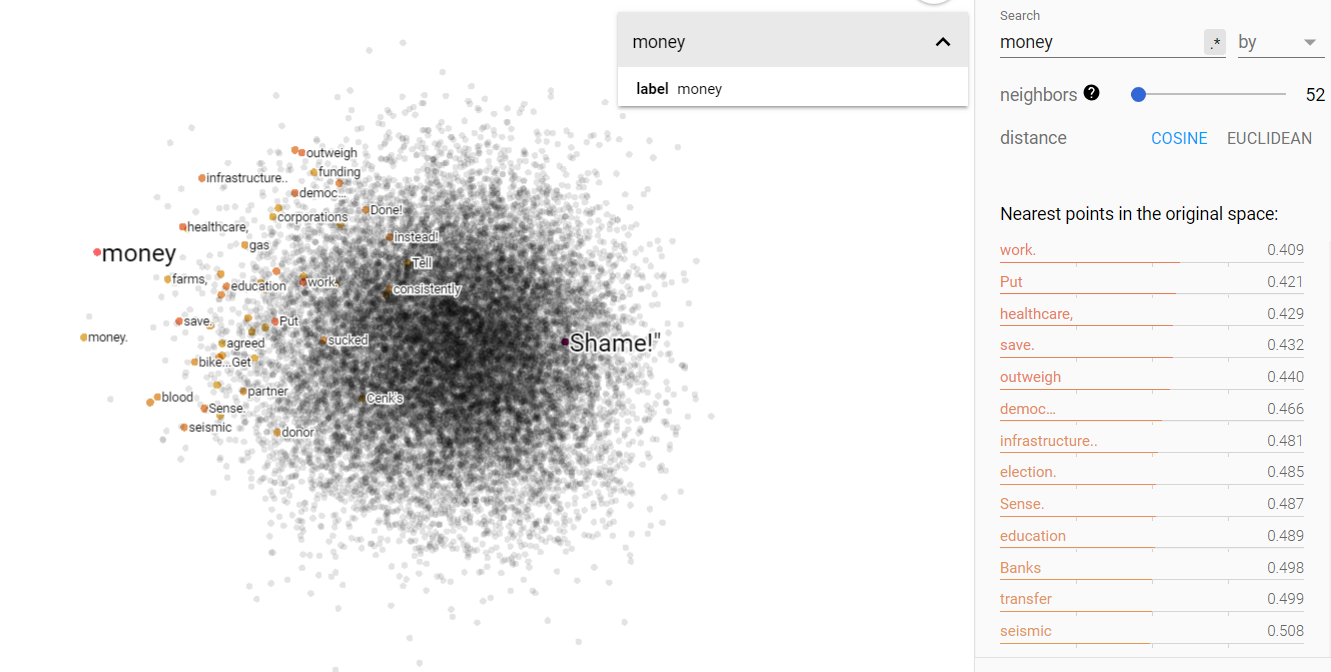
Money and environment on the projected vector V(‘money’ – ‘environment’) from the Brown corpus.
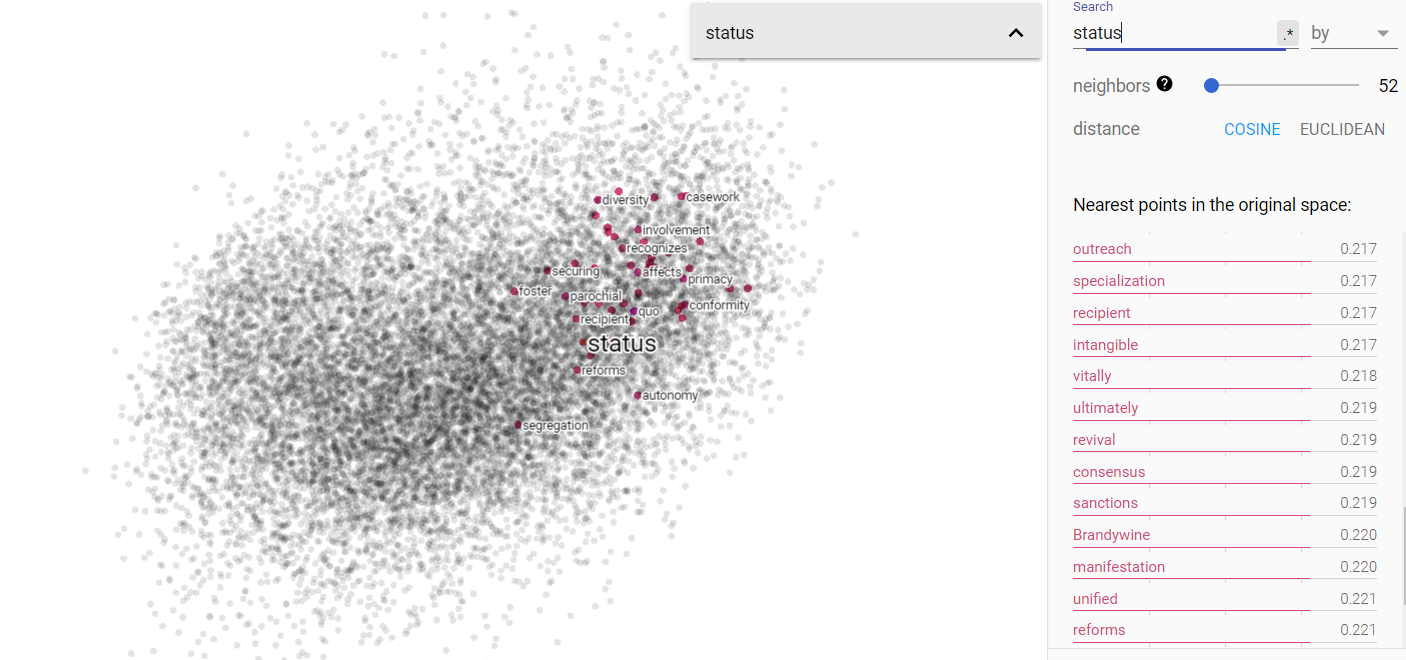
Status and science on the projected vector V(‘money’ – ‘environment’) from the Brown corpus.
From the above figures, we can see that the projected vector space for V(‘money’ – ‘environment’) is fairly disjoint; money and environment do indeed occupy separate ends of the 1960s spectrum. Furthermore, querying for status and science show that both are more closely related to the environment end of things. This was surprising; I was very much expecting status to be associated with money and I thought science would be more money neutral.
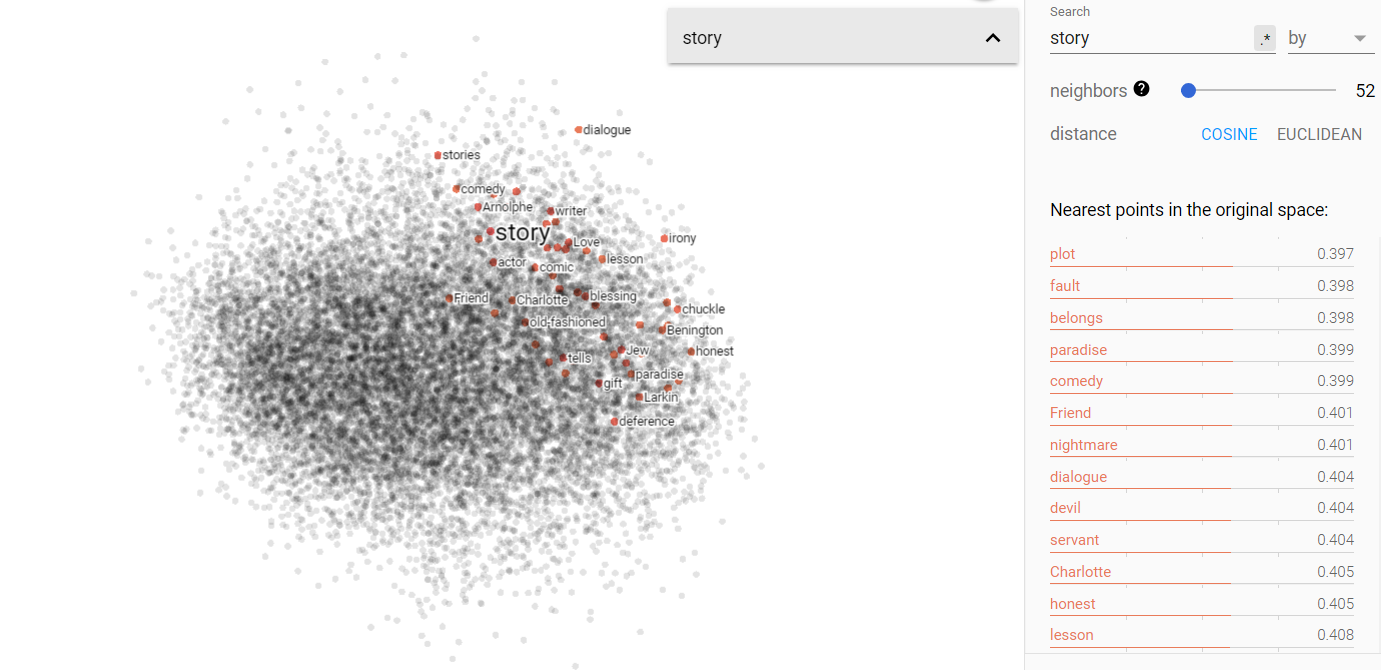
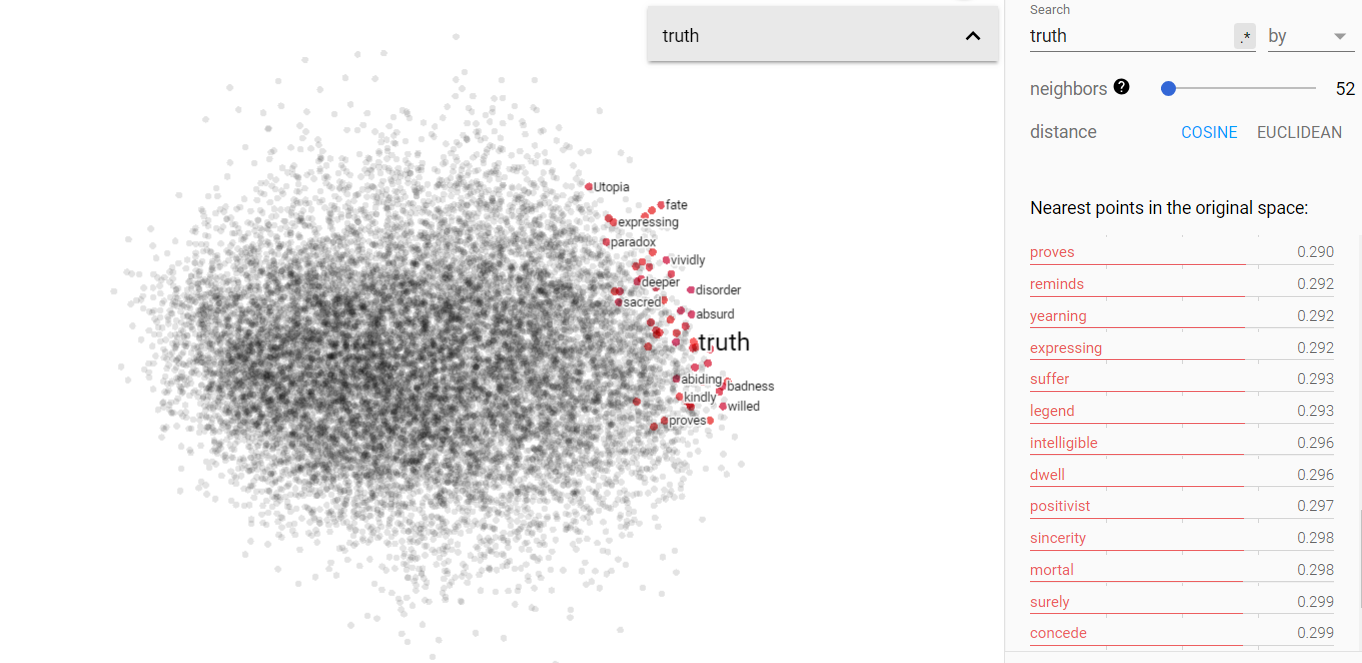
Story and truth on the projected vector V(‘story – ‘truth) from the Brown corpus.
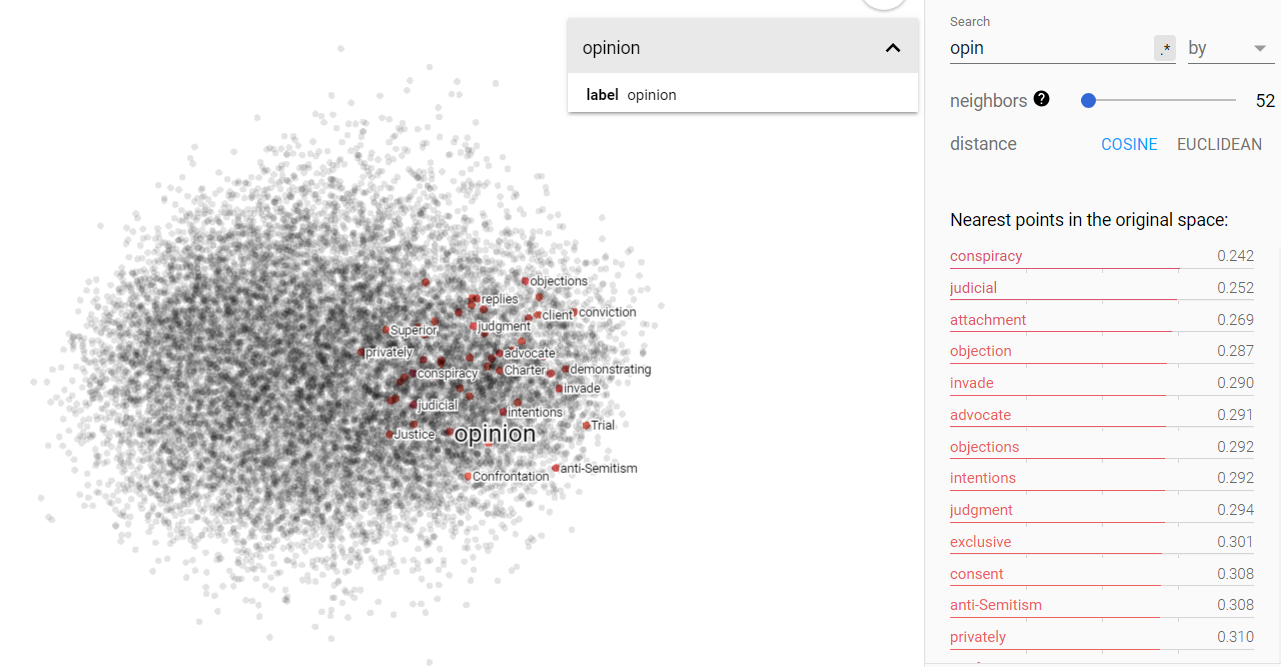
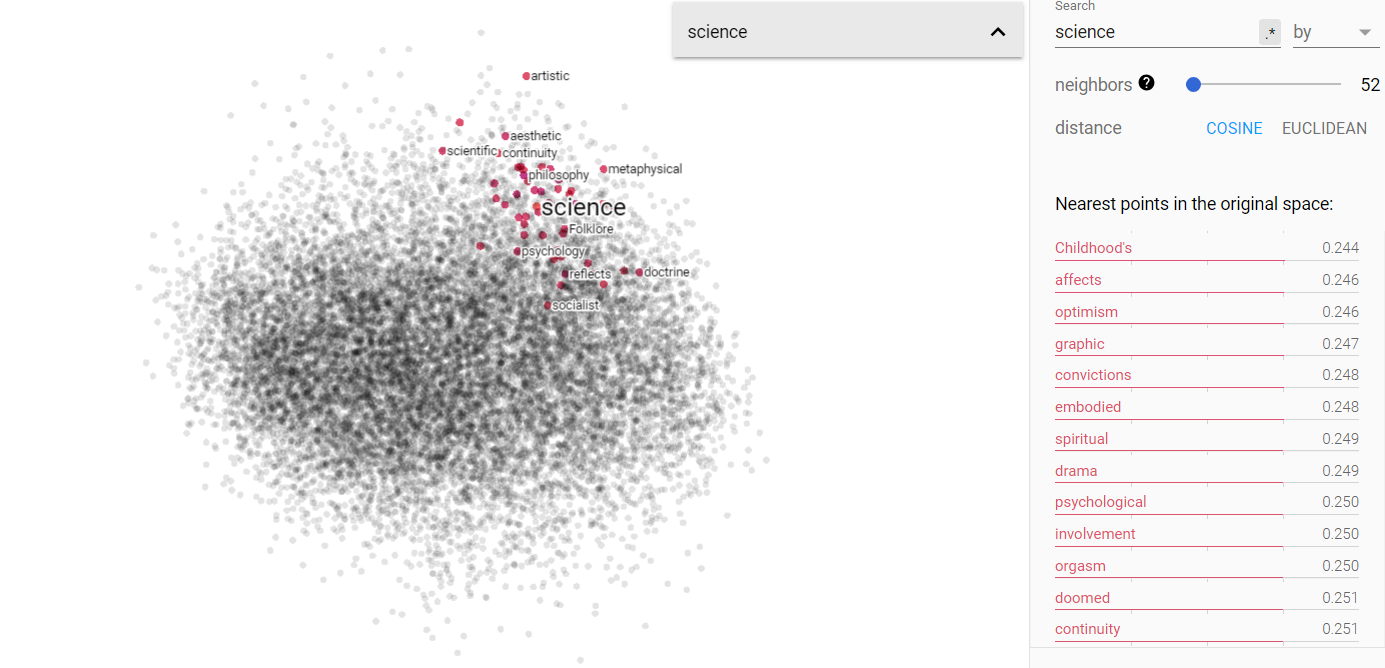
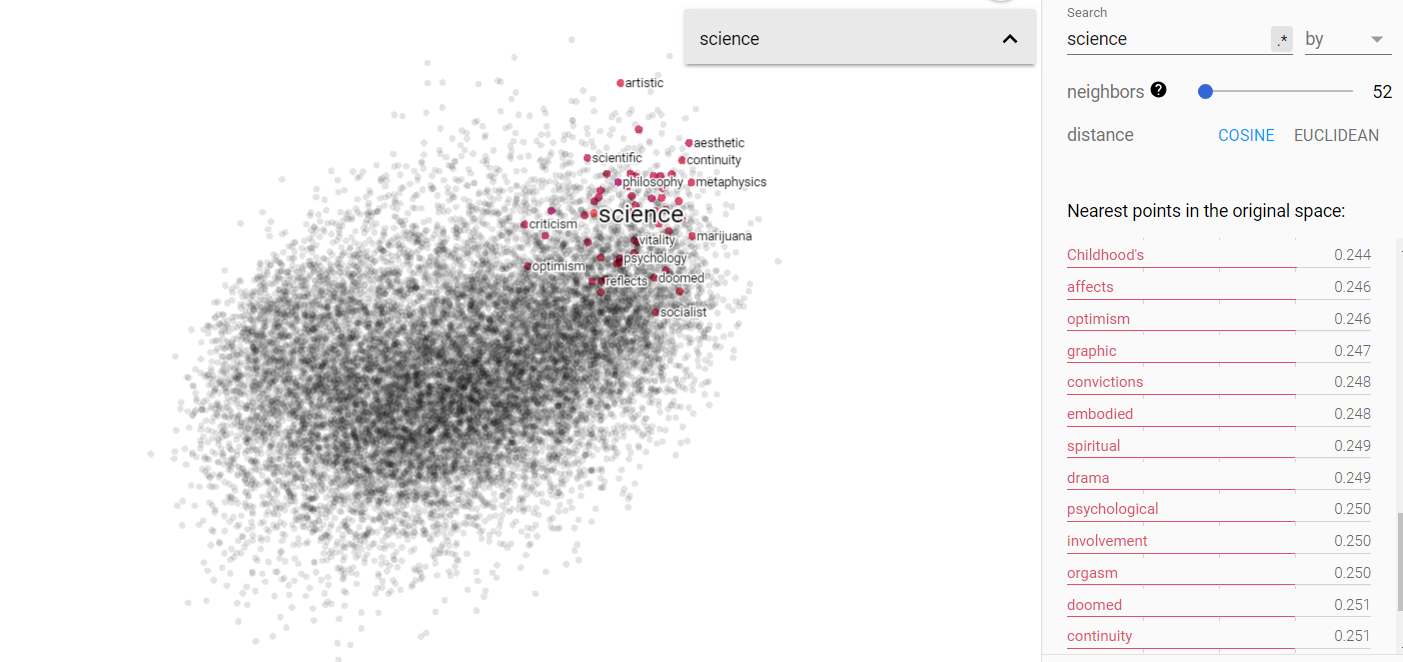
Opinion and science on the projected vector V(‘story – ‘truth) from the Brown corpus.
Above we can see the projected story/truth vector space. Interestingly enough, my assumptions were yet again challenged. I expected that truth and story would be more disjoint, but in fact, they occupy very similar vector spaces. Furthermore, I was astonished to find that science is more closely associated in this space with story, while opinion is more closely related to truth! I think this says something more fundamental about human nature, but I will leave that for the conclusion section.
Climate
Now that’s look at the contemporary data and see what changes we can find. First, the climate data:
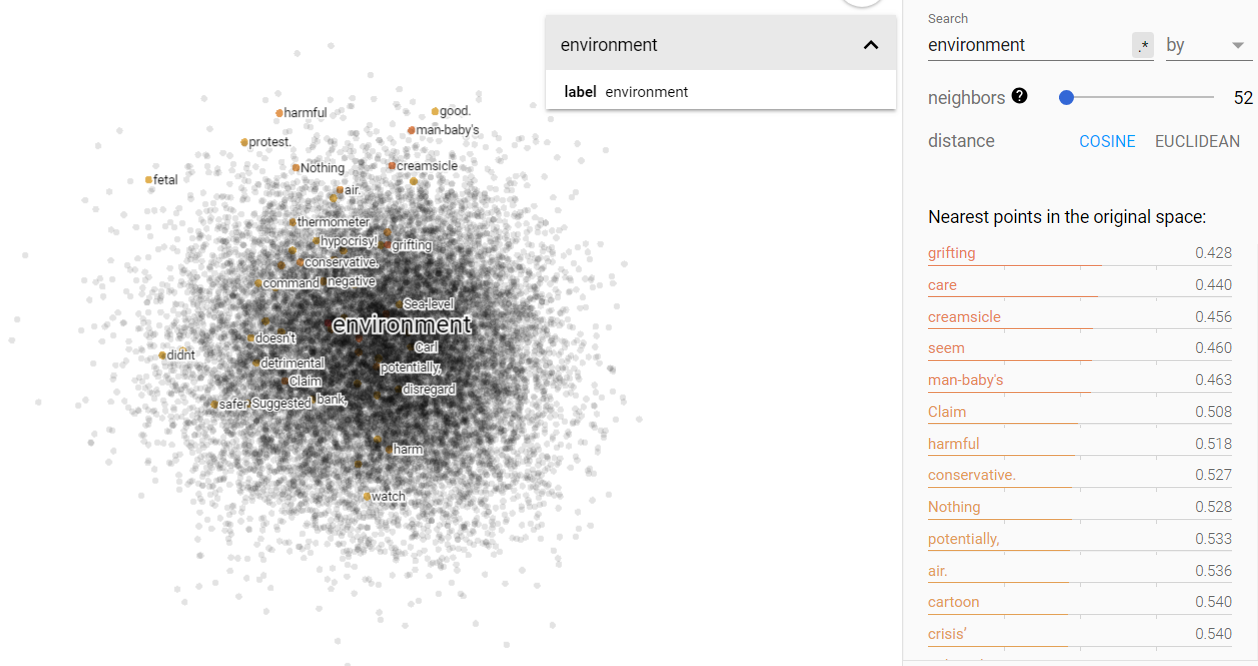
Money and environment on the projected vector V(‘money’ – ‘environment’) from the climate corpus.
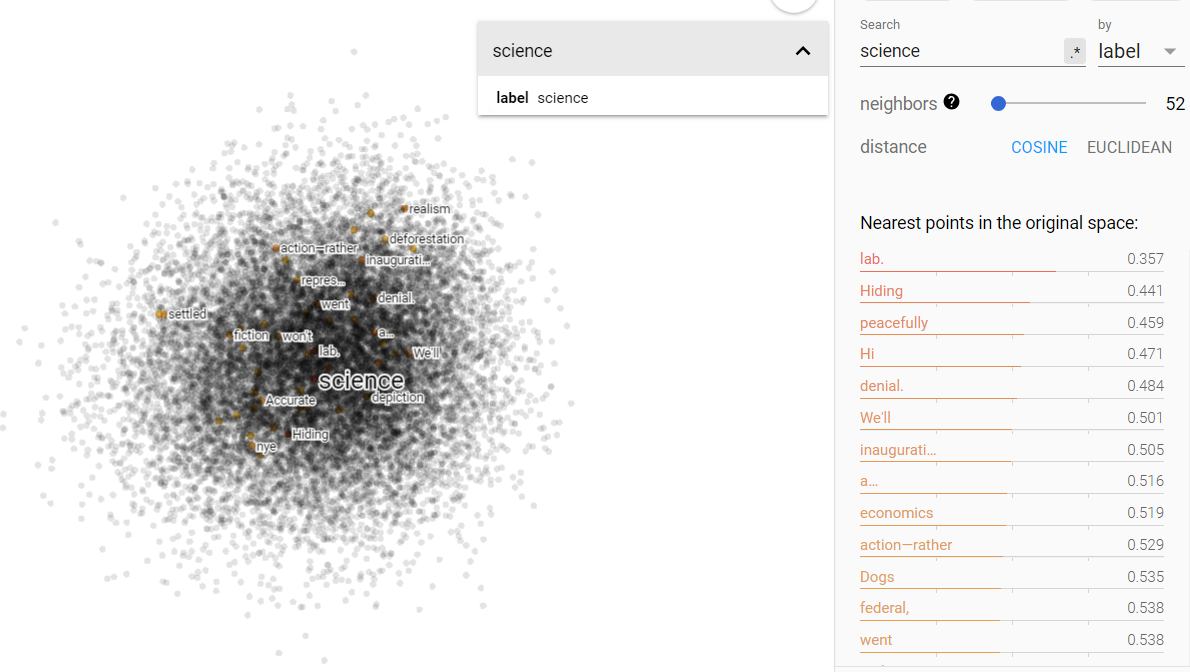
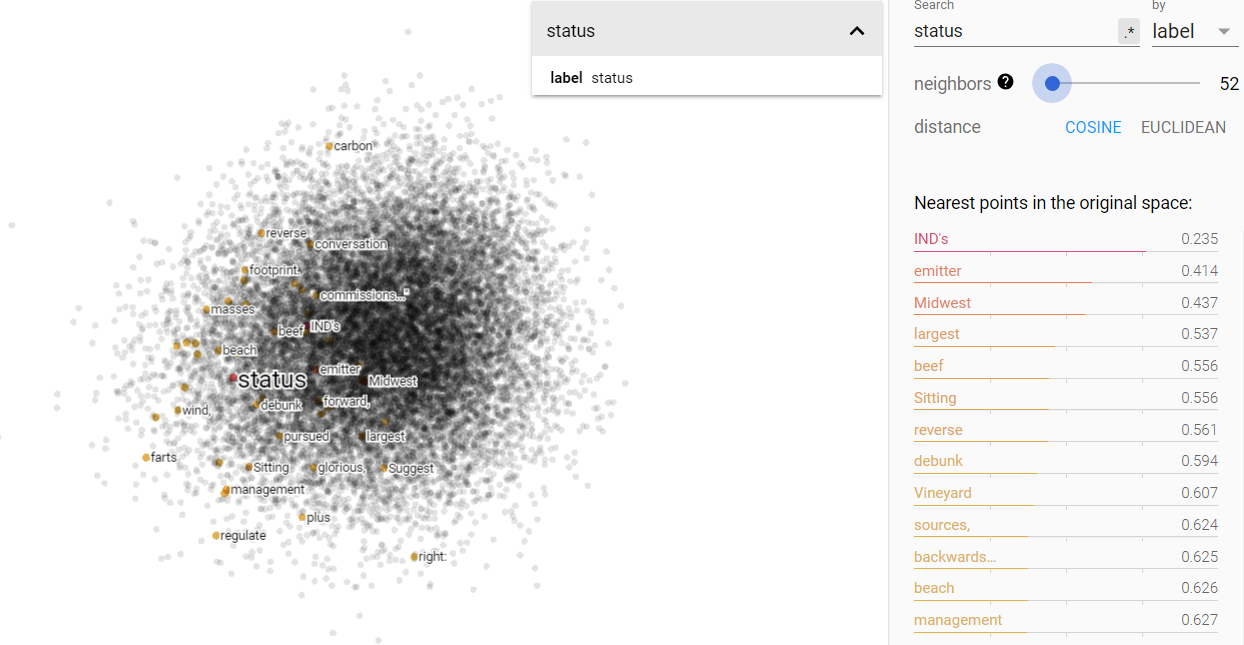
Status and science on the projected vector V(‘money’ – ‘environment’) from the climate corpus.
A change has occurred from the Brown corpus in terms of status and science in the money/environment vector space. We see that money and the environment are no longer so disparate and are in fact more closely related than before. Science still remains close to the vector space of environment, but I was surprised to see that status shifted significantly more towards money. That shift may indicate an increase in classism of the last half-century. I hypothesize that such a shift would be sensible with the regards to the increase in contempt of science, because public money could be spent on normalizing class divides rather than be spent on scientific endeavors.
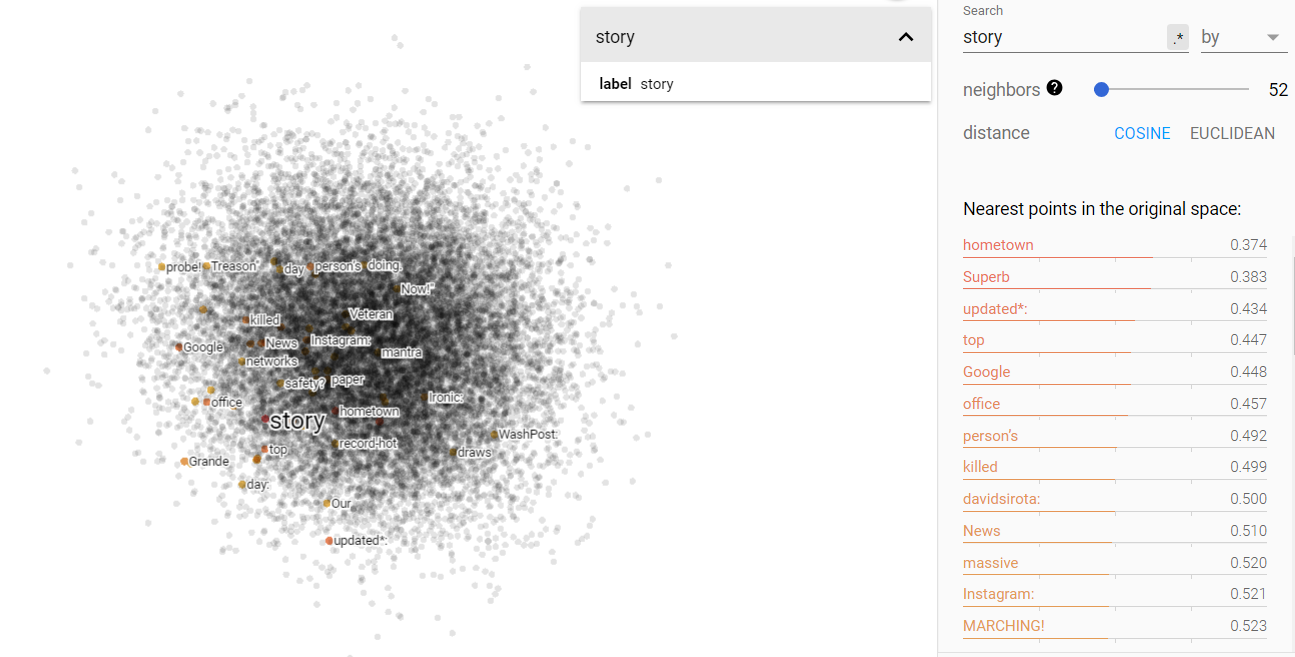
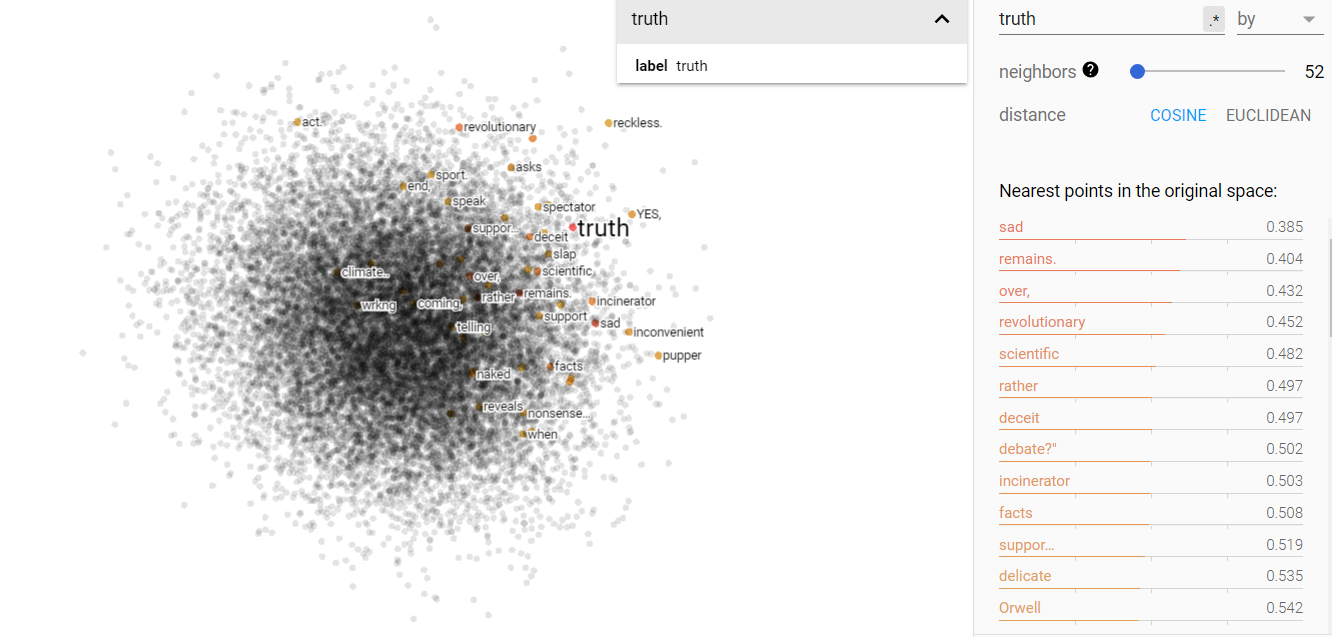
Story and truth on the projected vector V(‘story – ‘truth) from the climate corpus.
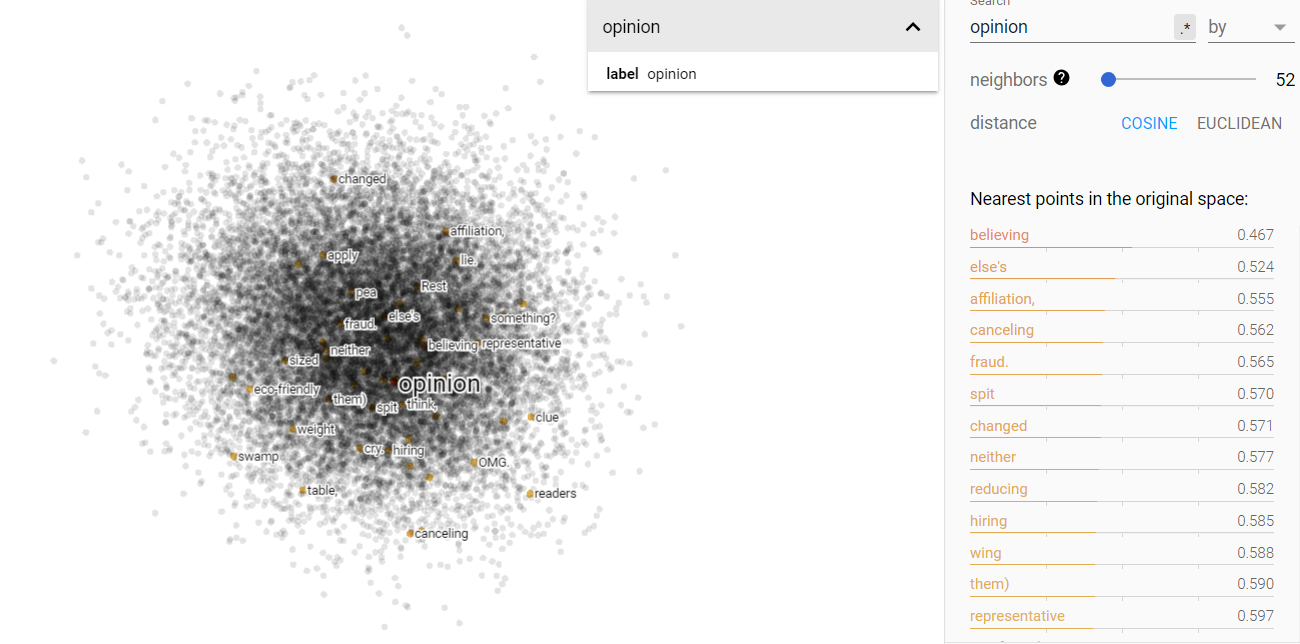
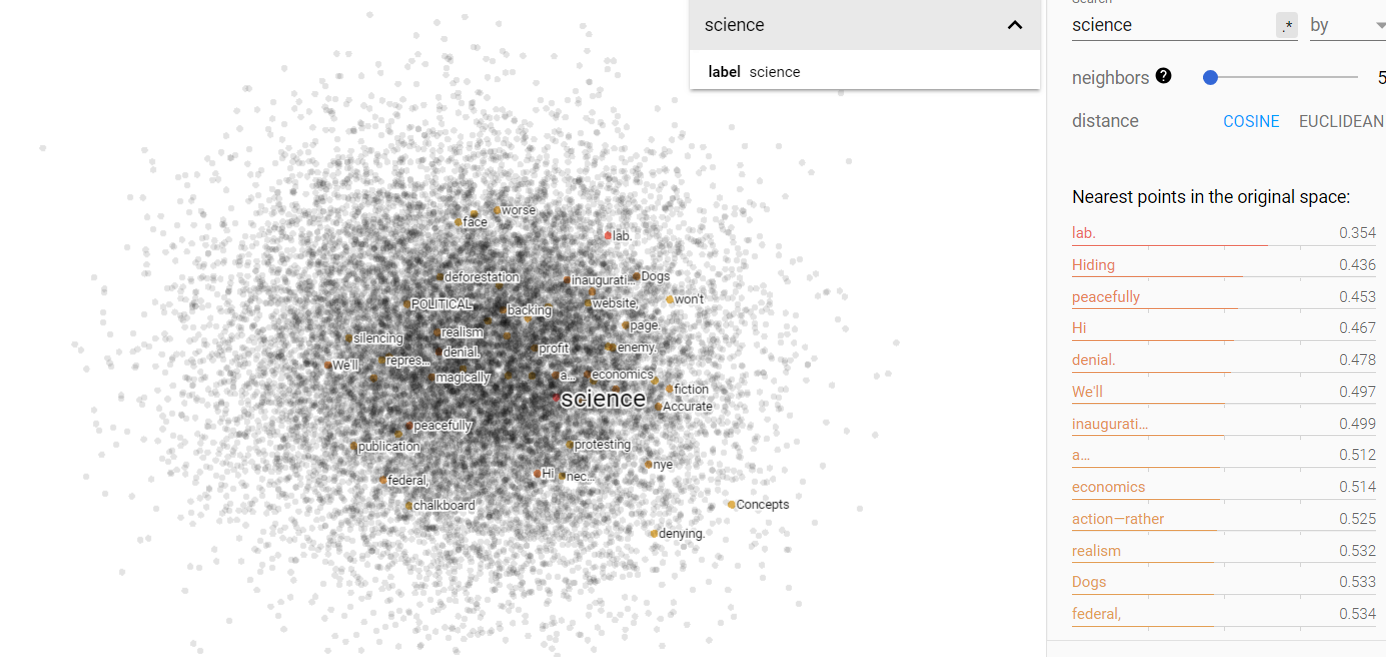
Opinion and science on the projected vector V(‘story – ‘truth) from the climate corpus.
Here we see that the climate data shows us an evolution: both opinion and science have moved away from the story side of the vector space and towards the bottom right. But, they both haven’t really moved more toward the truth side for the vector space. To me, this might mean that opinions and science are both formulated more independently based on cultural factors, rather than objective truth or what the media tells us.
March for Science

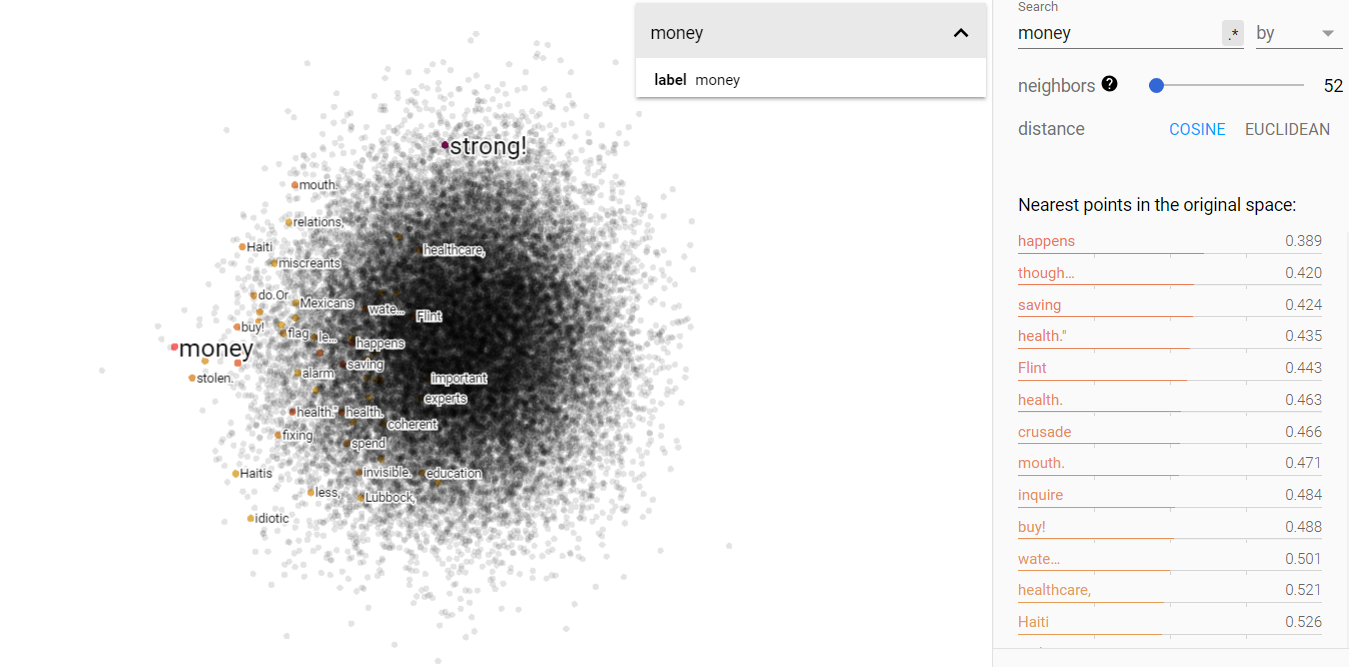
Money and environment on the projected vector V(‘money’ – ‘environment’) from the march for science corpus.
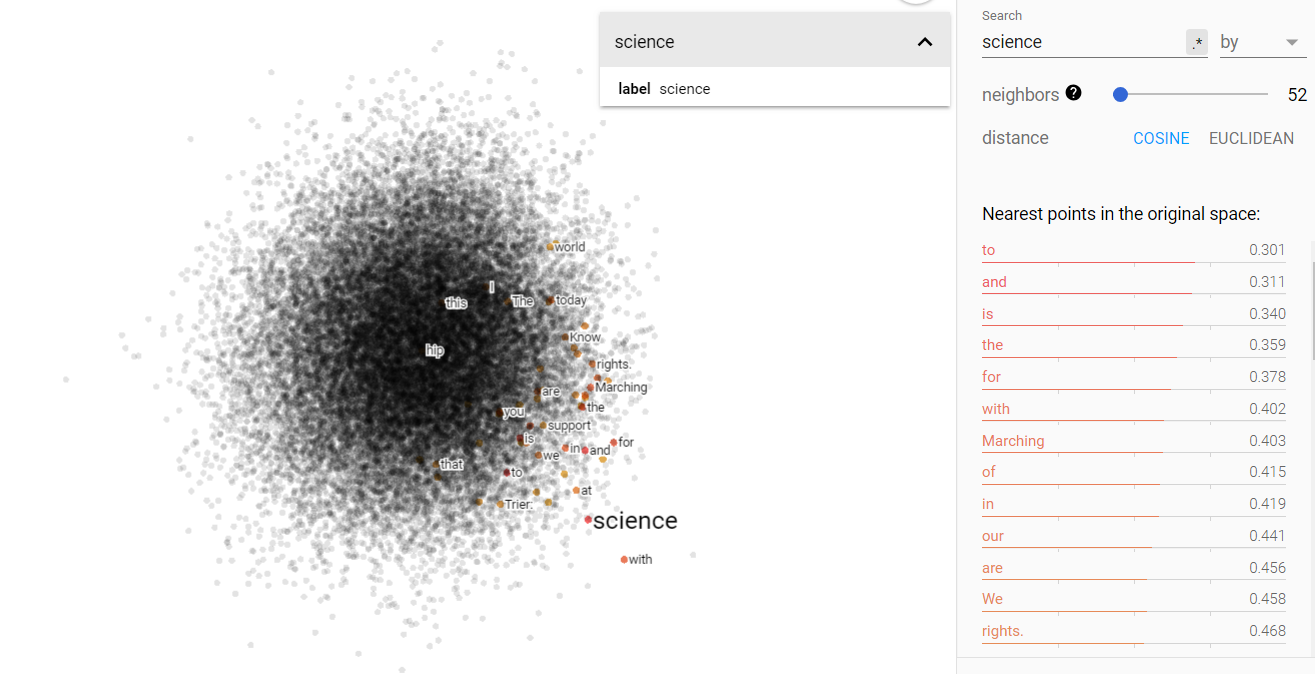
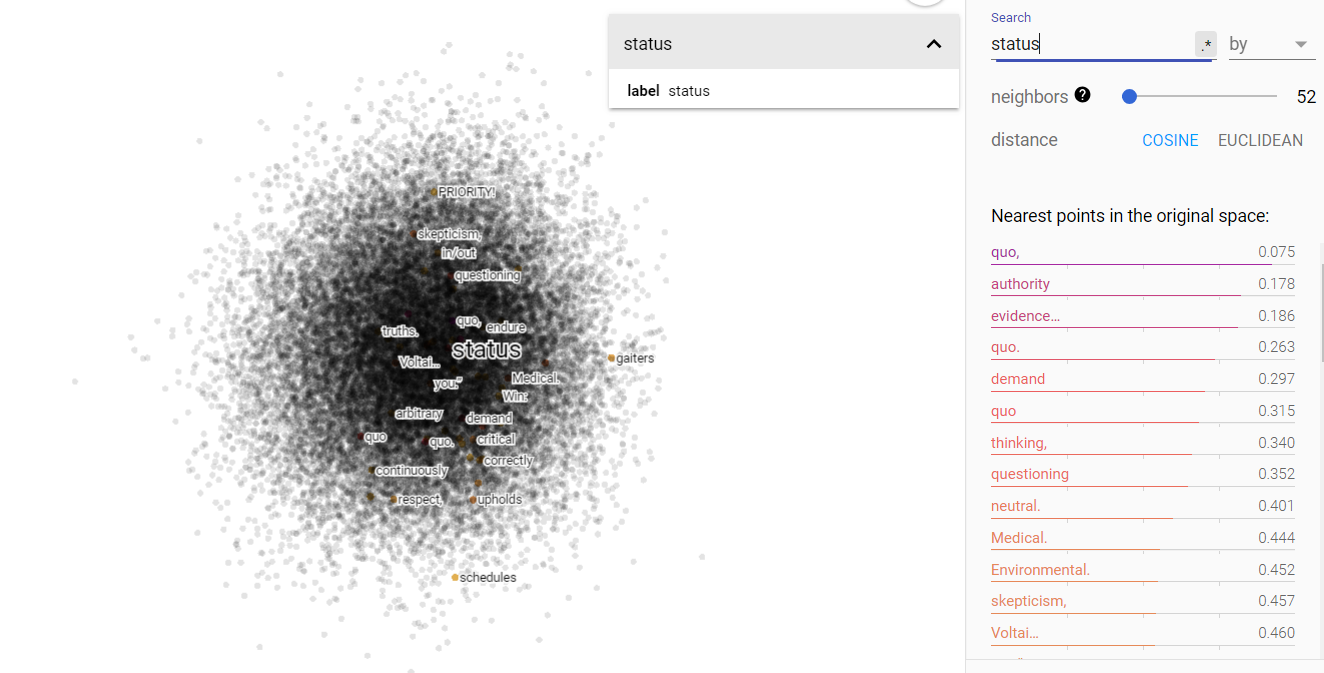
Status and science on the projected vector V(‘money’ – ‘environment’) from the march for science corpus.
Unlike the other contemporary data, we again see the disparateness between money and environment that was found in the Brown corpus. It wouldn’t be too unreasonable to conclude that there is some amount of separation still between those two concepts. And just like the Brown corpus, we find that science and status are more strongly associated with environment than money. I take this to mean that, while there is some indication of class shifts as evidenced by the climate data, money does not play a superior role in shifting influence. But I do think that what can be done with money can have a large influence, particularly in how it can be used to ‘buy’ narratives (looking at you Cambridge Analytica).

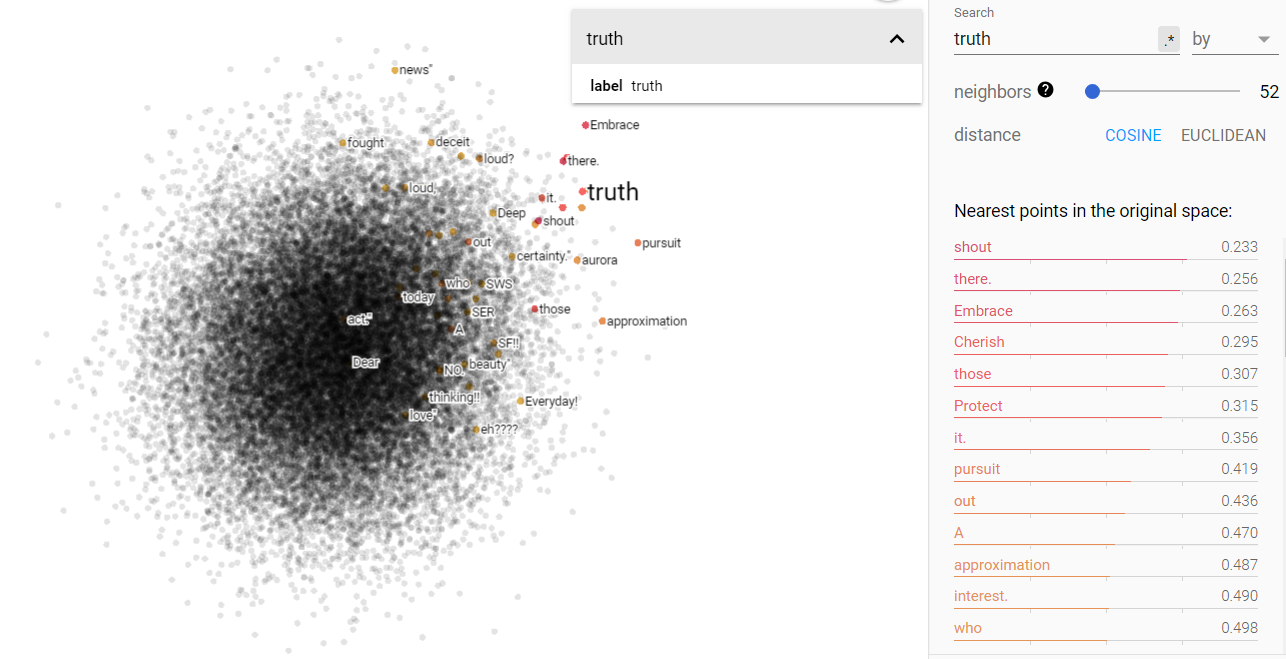
Story and truth on the projected vector V(‘story – ‘truth) from the march for science corpus.
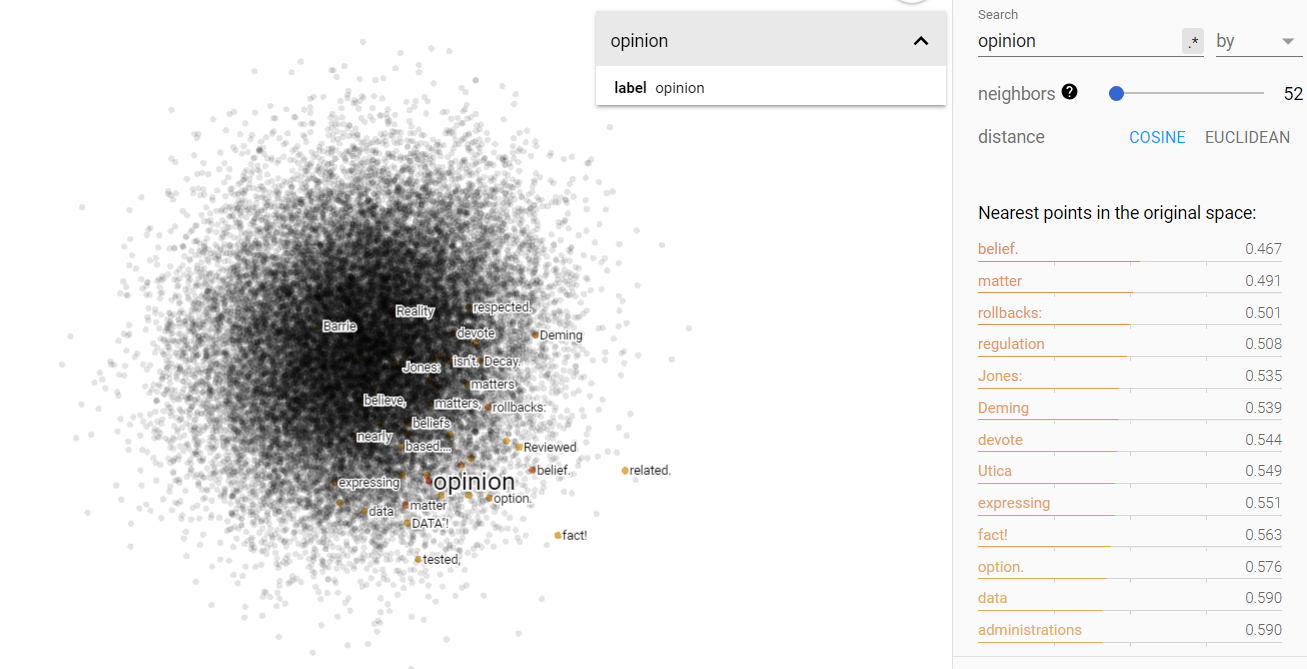
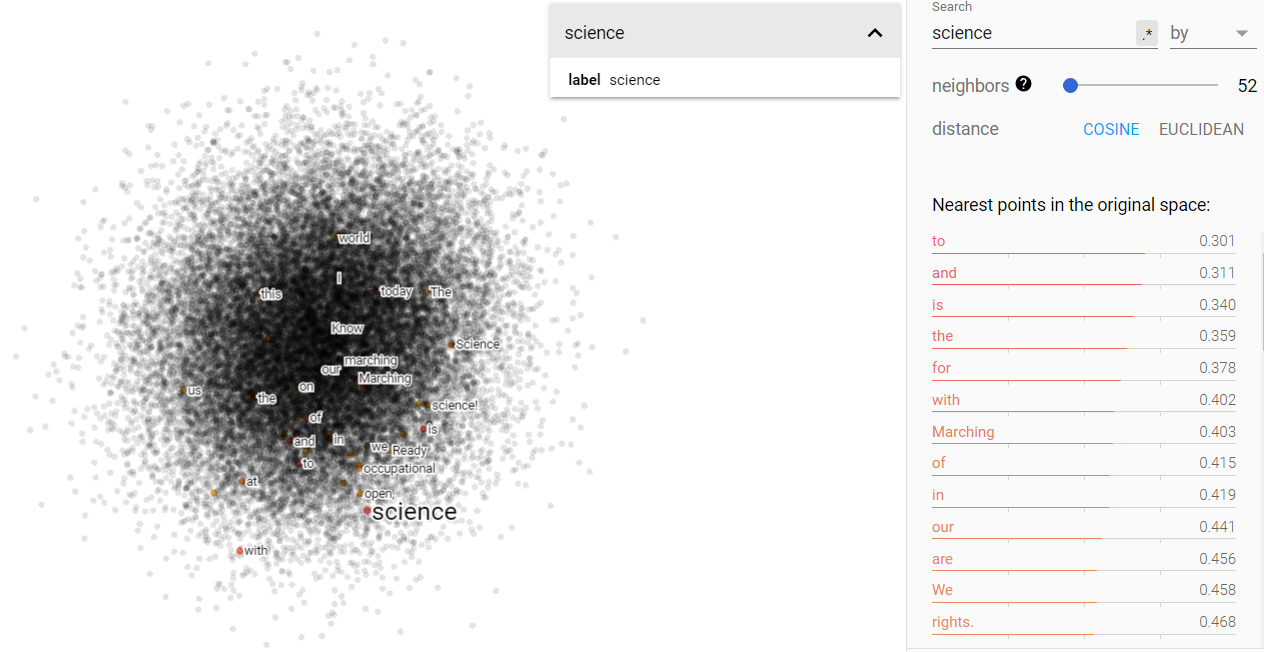
Opinion and science on the projected vector V(‘story – ‘truth) from the march for science corpus.
Lastly, we can see that opinion and science have largely differentiated themselves from both the truth and the idea of a story. I think this reflects the exact same change we saw in the climate data.
What Conclusions Can We Make?
I think there are a number of interesting conclusions to be made here. First, the data shows that identity politics have continued to shape culture since the 1960s, and that influence has its own bearing on perceptions of science. The modern identity of Trumpian America is itself reflective of some class struggle, but I think more broadly as a movement away from more collectivist thought and more towards individualism. And in that, we find that science is thought of less highly and more fearfully, as it is a practiced that is much enriched by collaboration and communication. Second, we can conclude from the data that scientific truth is really what you make of it; we can see it very clearly in the data. Science is not so much fact, truth, or even a story. Scientific truths are not self-evident; rather they are an opinionated form.
Extensions
In the future, I would like to use an unsupervised system for learning word representations called “Unsupervised Sentiment Neuron” and which is developed by OpenAI. This representation is developed through unsupervised methods, meaning that the representation is developed without any labeled data and trains itself in much the same way as word2vec does. However, OpenAI have showed that their representation has also learned to represent sentiment, something that I am relying on an existing (and therefore biased) model – VADER [7]. The problem is that the algorithm necessitates the use of a supercomputer.
I also tried using a predictive text model specializing in transfer learning developed by fast.ai [5]. This model, ULMFiT, takes a pre-existing model that has learned English grammar and applies state-of-the-art transfer learning techniques to create a model capable of predicting the next words in a sentence (this is also how the “Unsupervised Sentiment Neuron” functions). I would like to use this as a form of querying the dataset and literally “asking” the data questions. Again, this methodology required too much compute for me to handle on my poor little desktop.
Finally, I attempted to do some sentiment analysis and got as far as labeling all of my data using VADER [7], but lacked the ability to create a compelling visualization in time. Later on, I would like to map out the different sentiments that are apparent in my corpora.
References
- Mart´ın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Man´e, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Vi´egas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Largescale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- D. Duhaime. Clustering Semantic Vectors with Python, 2015.
- W. N. Francis and H. Kucera. Brown corpus.
- Ann Hillier, Ryan P. Kelly, and Terrie Klinger. Narrative style influences citation frequency in climate change science. PLOS ONE, 11(12):1–12, 12 2016.
- Jeremy Howard et al. fastai. https://github.com/fastai/fastai, 2018.
- Montan˜a C´amara Hurtado and Jos´e A. L´opez Cerezo. Political dimensions of scientific culture: Highlights from the ibero-american survey on the social perception of science and scientific culture. Public Understanding of Science, 21(3):369–384, 2012.
- C. J. Hutto and E. E. Gilbert. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Eighth International Conference on Weblogs and Social Media (ICWSM-14), Ann Arbor, MI, 2014.
- Michael D. Jones. Cultural characters and climate change: How heroes shape our perception of climate science. Social Science Quarterly, 95(1):1– 39, 2014.
- Jason S. Kessler. Scattertext: a browser-based tool for visualizing how corpora differ. 2017.
- owygs156. K means clustering example with word2vec in data mining or machine learning. 2017.
- A. Patel. Nlp analysis and visualizations of presidentinvaalit2018. News from the Lab, 2018.
- Radim ˇReh˚uˇrek and Petr Sojka. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45–50, Valletta, Malta, May 2010. ELRA. http://is.muni.cz/publication/884893/en.
- Nick Ruest. climatemarch tweets april 19-may 3, 2017, 2017.
- Nick Ruest. marchforscience tweets april 12-26, 2017, 2017.
- Mohammad Salehan, Dan J. Kim, and Jae-Nam Lee. Are there any relationships between technology and cultural values? a country-level trend study of the association between information communication technology and cultural values. Information Management, 55(6):725–745, 2018.
- Mark A. Thompson. Space race: African american newspapers respond to sputnik and apollo 11. Master of Arts (History), 2007.
- Arun Vishwanath and Hao Chen. Personal communication technologies as an extension of the self: A cross-cultural comparison of people’s associations with technology and their symbolic proximity with others. Journal of the American Society for Information Science and Technology, 59(11):1761– 1775, 2008.
Appendix
I created lots of code and files throughout this project. Here is a rough outline of the file structure of my project:
- Scripts that helped me parse the data (/scripts)
- An experiments IPython notebook containing the main body of code that I used to test different hypothesis and techniques (experiments.ipynb)
- A folder containing various pretained models and vectors (/models)
- A folder containing files for graphing in Gephi (/graphs)
- Various images relevant to this project (/images)
- JSON config files for the embedding projector made by TensorFlow (/json)
The words in the parenthesis describe the relevant file or folder which are all housed in a GitHub repository you can find at https://github.com/ndalton12/nlp-english-project. I won’t post more code or pictures here because it will take up way too much space and everything is already on that GitHub. Feel free to contact me at dalton.n@husky.neu.edu if you have any questions about the files or work here.