The Challenge
Ask any Political Science undergrad about data analytics, and they’ll probably have a vague sense that it’s something social scientists use. But most of us don’t have experience with computational methods, despite their potential to provide a whole new toolkit with which to explore social issues. College curricula in the social sciences don’t emphasize data skills, and delving in can seem daunting to someone who’s never been exposed to coding before. Of course, an entire field of professional researchers is dedicated to working in computational social science. But at the undergrad level there is very little cross-pollination between the disciplines.
So what’s a Poli Sci major to do? Is it possible to learn enough about coding to do cool research projects, without having to torture yourself and take the weed-out intro level CS classes? I’ve set out to do just that. This particular project utilizes some of the skills I’ve learned this semester, but is also intended to provide accessible explanations of the process to other non-CS undergrads who are interested in dabbling with computational techniques. If you had asked me a few months ago what Python is, I would have said it was a large snake. So if I can do this, anyone probably can.
The Question
Twitter data is a research goldmine if you can figure out how to tap into it. Hundreds of millions of active users discussing the issues of the day interactively, in real-time, with geo-tags to boot? I knew this was where I wanted my corpus to come from. Researchers have used it to predict enrollment in the Affordable Care Act, analyze psychological differences between Democrats and Republicans, and study public behavior in the aftermath of mass tragedy, among many other interesting topics.
When I first learned about word embedding models, I was particularly interested in their potential to deduce findings independent of human reasoning. Could I use this to look for interesting and surprising findings, rather than confirming a hypothesis that I had already come up with based on my own limited intuition? Using word2vec in RStudio, I could input a dataset of Tweets and it would quantify the proximity between words. Using k means clustering, I could then get a list of vectors (i.e. groupings) that are randomized and representative of the dataset.
Around the same time that I learned about word embedding models, we were covering micro targeting in my campaign strategy class. Based on massive voter data files, campaigns and private companies can find seemingly random correlations to predict how someone will vote. Do you own a cat and shop at Whole Foods? Perhaps that means you likely voted for Hillary. I don’t actually know because I don’t have access to these voter files, but you get the idea.
If political campaigns can find spurious correlations between consumer behavior and voting behavior, surely I could find some interesting connections between topics of discussion on Twitter. And so my research question began to take shape. First, I’d have to put together a dataset of people who care about a given issue enough to talk about it on Twitter. Then I’d look at the vector space for all of their Tweets. The question I was looking to answer was something like, “What do people who care about a given issue also care about?”
I decided to go with healthcare as my topic for the purposes of this project. If I could understand how to approach this specific topic in a way that was replicable and generalizable, the same process could be applied for different topics over time. In the future, I plan to also look at immigration, education, and other keywords to see what I can learn about public discourse. For now, though, I proceeded with my refined research question guiding me onward: “What do people who Tweet about healthcare also Tweet about?”
The Corpus
I used https://tags.hawksey.info/ for the initial Twitter scrape, which was developed by Martin Hawksey. It’s quite user-friendly: just type in a word to query and it returns thousands of Tweets right to your Google Drive. The downside is that it can only scrape very recent Tweets, but it’s a great starting point for anyone looking to do Twitter research without an extensive background in coding. I scraped twice within a 3-week span, querying the word “healthcare”. The spreadsheet has a column for user ids, so I downloaded them as a file. And just like that, I had a list of users who have Tweeted about healthcare.
This is where things started to get more complicated. I had to apply for a Twitter developer account, which gives me access to their API. An API, I learned, is an application programming interface. That’s really just a fancy way of saying that my computer now has permission to talk directly to the Twitter server. I also downloaded the Twitter module for Python, which is a package of coding tools for working with Tweets.
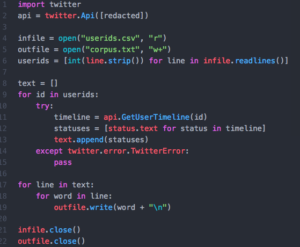
I wrote this Python script to pull the Tweets from each of my healthcare Tweeters. Some people have privacy settings that prevent me from scraping their timeline, so I had my program skip them. Anyone wishing to try something similar should apply for their own Twitter API key and insert it in the second line. I left mine out of the screenshot, because apparently those are supposed to remain secret. It’s worth noting that this script only returns around 300,000 words at a time. For reasons probably related to Twitter’s API limits, I actually ended up running variations of this code several times to produce files with enough words.
The way I constructed this corpus makes it different from many other Twitter corpora in at least one important way: the Tweets aren’t organized chronologically. Although my initial scrape for user IDs was based on recent Tweets, the script I wrote does not have any such temporal limitations. The timeline of each Tweeter is scraped in its entirety, as if I had compiled many people’s journal entries but kept the journals intact.
The Results

These were the results of the k means clustering in RStudio. No matter how many times I ran the function, I got a few clusters that were mostly noise. For example, cluster 7 is somewhat incomprehensible, and cluster 10 appears to be mostly Twitter handles. If I want to get more streamlined results in the future, I can preprocess the data to get rid of handles. But some degree of messiness seems to be unavoidable when working with Twitter data.
Based on theses initial clusters, I wanted to learn more by querying a few specific words. For instance, what was going on in cluster 8? To investigate, I queried the word “wife”.
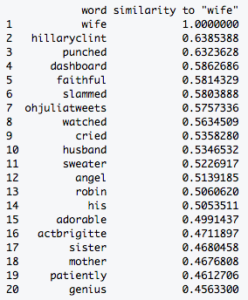
Some of these results are predictable, like “sister,” “husband,” and “mother”. But what’s up with “punched” and “dashboard”? A quick Google search revealed the answer. It seems that there was recent case in Ohio where a man got a lenient sentence despite punching his wife and slamming her head into the dashboard. After getting out of prison after only 9 months, he killed her. This appears to have been prominent in the national conversation.
I was surprised to find “hillaryclint” as the second highest-scoring word for “wife”. It seems to be capturing the first part of Hillary Clinton’s Twitter handle, so any mention of her would register. What happens when I query “hillaryclint”?
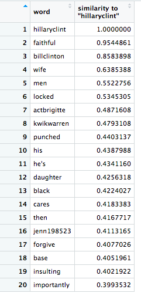
The results vary wildly, from positive words like “faithful,” “cares,” and “importantly,” to negative ones such as “locked,” “punched,” and “insulting”. One might conclude from this that Twitter users are polarized on Hillary Clinton, which would be an accurate reflection of the electorate.
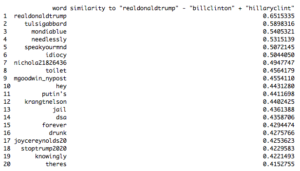
The closeness between Bill and Hillary Clinton’s respective Twitter handles made me wonder if other presidents and first ladies are similarly linked. Using the analogy feature of word2vec, I queried Obama’s Twitter handle to see what would be similarly proximate as Bill and Hillary are to each other. In other words: what is to Obama as Hillary is to Bill Clinton?
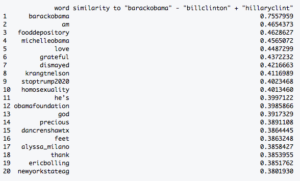
Unsurprisingly, Michelle Obama’s handle is one of the top results. And what about our current president and first lady? Interestingly, Melania Trump’s handle is nowhere to be found. If we were just looking for the highest-scoring woman, we might conclude based on word2vec that Tulsi Gabbard is the first lady.
The Implications
I wanted to first gather the data and then try to find the story it had to tell. I intentionally avoided coming into the project with a preformed hypothesis (e.g. “people who Tweet about healthcare also Tweet about Obama”). Word embedding models lend themselves to a deductive approach, with their ability to find patterns humans might not have predicted. Of course, it’s still up to the researcher to follow their intuition where it leads, as I have done in my president/first lady queries.
As they stand currently, my results lack scientific validity. In order to make any specific claims about healthcare Tweeters, I would need to make a separate corpus of Tweets randomly selected from users among the general population. I could then compare the results to the control group to see what is unique about healthcare Tweeters. To have a realistic hope of finding a statistically significant difference between the two groups is beyond the scope of this project. For my first foray into Twitter analytics, I was hoping to simply explore the terrain.
Now that I have a methodology with which to scrape data from a subset of Twitter users and analyze them using word2vec, I can replicate this with various topics and keywords. Students of the social sciences can follow a similar process to go in any number of different directions for their research. The possibilities are endless. Take, for example, a corpus of Tweets from people who care about immigration. Are they more likely to also talk about education? Are people who talk about Hillary Clinton more likely to talk about cats or dogs? I don’t know. Let’s find out.