Introduction
Friends is a popular TV sitcom that aired from 1994 to 2004. It’s a show that even if you haven’t watched it yourself you’ve likely heard of it. Personally, this is a show that I have watched and rewatched many times without losing any of my fixation on it. However, I’ve come to realize that TV shows like friends, movies, and other media have subconsciously come to influence how viewers approach real-life relationships. The portrayal of solely heterosexual relationships or other stereotypical romantic ideals in popular media tends to negatively young people’s beliefs about the relationships they encounter (Hefner, Veronica). This has led me to focus on pursuing the following research questions:
- How are stereotypical heterosexual relationships represented in the popular TV series Friends?
- How are diverse/other relationships represented in the popular TV series Friends, if at all?
Through these different questions, I wanted to investigate how a specific show, Friends, reflects common traits in relationships and exaggerates other aspects of romantic relationships. It’s important to note that this show aired 17 years prior to the present day. However, the show is still widely viewed by youth today so I believe the themes of the show are still relevant to current viewers as well.
Choosing My Text Corpus
In order to effectively train a model and run queries on it, we needed a corpus of at least 600,000 words with over a million words being preferable. To accomplish this grand scale of analysis, I used a word-embedding model to explore the relationship between words in my chosen corpus. The model is called word2vec, and I used it to build a vector space model, turning the words in my corpus into vectors. These words are positioned in the vector space based on whatever contexts or usages they have in common. Author Ben Schmidt has an informatory post on word2vec in greater detail here if you’re interested. Below is a visualization of my vector space model for my corpus.
My vector space model may look very cluttered and disorganized, but it was made to represent a single text. My final corpus consists of the entire transcribed script of the TV series Friends which aired from 1994 to 2004 and altogether has 873,251 words. Again this is on the lower end of words needed to accurately train a model as over a million words would be ideal. I found my corpus on Kaggle and it was already completely cleaned up, downloadable as a .txt file, and ready to use for training my model. Divyansh Agrawal was the person who scraped this data from the Friends tv-series and provided the data set for public use. Since the script was already in its final form and I didn’t have to do any data preparation, all I had to do at this point was train my model using RStudio. I trained my model with 350 iterations in order to minimize random errors while still making the model decently trained. In future work, I would like to try more iterations, time permitting. However, for the purposes of my research question, I believe the number of iterations I chose was appropriate and yielded detailed results about my text corpus for analysis.
Querying Relationship Roles
The series itself focuses on relationships, everything from the title of the show being Friends to the interactions of the characters in the series broadcasts an instance of what the show believes a relationship should be. Since my focus was on romantic relationships I decided to start off with some standard “closest to” queries with the terms “Boyfriend”, “Girlfriend”, “Husband”, and “Wife”. When using word2vec for data analysis, words with a similarity score of around 40% or higher are considered similar enough to be of significance. This led me to look for words that fall within the +40% range of similarity considering the size of my corpus. The higher the similarity score percentage of the resulting word the more related that word is to the word being queried. I then looked for commonalities between these initial few query results and ran queries on them to see if there were any further patterns. When I first trained my model with 150 iterations (the default amount) I noticed that most of the results were above 40% similar, however when I increased the iterations to 350 the similarity scores decreased to around 20%.

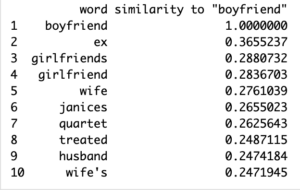
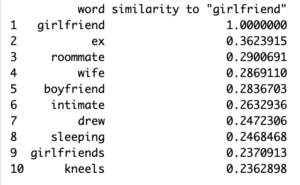
The most interesting result I found was one of the most common results from the queries for the words”Boyfriend”, “Girlfriend”, “Husband”, and “Wife” is “ex”. Other similar terms represented the idea of relationships ending for whatever reason. Words such as “cheat” and “affair” were more common than words with an emphasis on stability like “marriage”/”married”. These words all seemed to tie to a dysfunctional or short-term relationship paradigm which can be problematic for an impressionable audience who might come to believe that cheating/affairs are commonplace behavior (Hefner, Veronica). Curious about what further ties there were to relationships ending, I next queried terms stemming from “ex” like “divorce” or “breakup”.
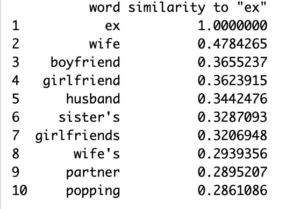
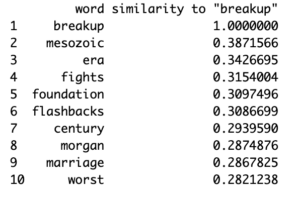
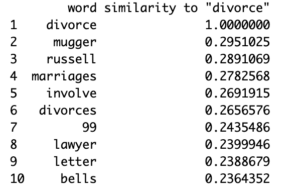
I thought it was intriguing how there weren’t too many similarities amongst these three searches, besides “breakup” and “divorce” involving a lot of negativity, for instance, results like “fights” and “worst”. A basis for these results is very likely two of the main characters Ross and Rachel (played by David Schwimmer and Jennifer Aniston respectively) dated then separated on the show. To be fair, dating and then separating or getting married then divorced is normal behavior but the circumstances that lead to splitting are where the problem lies. Themes that would be problematic for impressionable audience members potentially lie in what shows portray as adulterous or scandalous.
Further Into HeartBreak and Divorce
To further explore this idea, I wanted to look into means that could result in a dramatic or ugly split. I ran my next queries on “cheat” and “affair” in order to accomplish this.
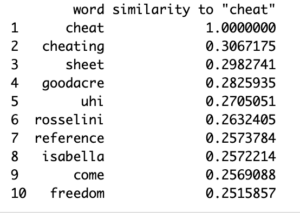
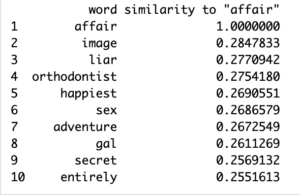
These results were ambiguous to say the least but nonetheless informative to my research question. The results for “cheat” were mostly irrelevant but the last result “freedom” caught my attention, leading me to believe that the cheating was a result of wanting to be free of a relationship. The results for “affair” were much more eye-opening, with words like “happiest”, “sex”, “adventure”, and “secret” make me believe that the thrill of adultery or lack of happiness in a current relationship led to an affair. Adultery and unfaithfulness are especially common among new and young couples with these themes considered to be the most influential on young audiences through television series or other media, particularly the sexual aspects (Galician, Mary-Lou). Yet while these queries did shine a light on the reasoning for potentially ending a romantic relationship they didn’t quite fully explain the parties involved. I was also curious how diverse the script would be in terms of acknowledging the lgbtq+ community so I formed the following queries.
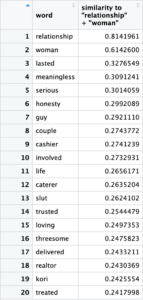
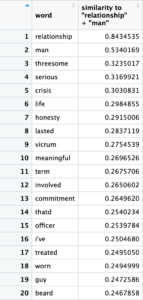

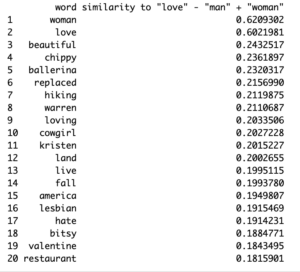
With the intent of coming full circle, from the conception of a relationship to its body to its end I decided to look into the components of a relationship by querying “relationship + woman”, “relationship + man”, “love – woman + man”, and “love – man + woman”. I was surprised to see that there was only one mention of lesbian of barely 20% similarity but other than that the themes of love and trust were the most common which was reassuring. However, results like “threesome”, “slut”, “meaningless”, “wasted”, and “hate” were very concerning especially given the context of the queries. The amount of negativity coming from relationships, in general, was offputting considering the show is supposed to be lighthearted. I’m sure if I had more time to dig even deeper the results would show more negativity and themes that promote unhealthy beliefs about relationships in real life or pursuing relationships romantic/otherwise.
Conclusions and Future Work
Through my research and queries on my word2vec model, I believe I discovered some compelling themes surrounding the portrayal of relationships in Friends. Using the research of Galician and Hefner to preface these themes that I chose to pursue and to help analyze the data, I found queries that demonstrate how relationships are portrayed in this specific televised series. To be concise, how the lifecycle of a romantic relationship shows up through labels like “boyfriend/girlfriend” and “ex”. As well as what occurs in between to get from together to separate, whether it be an affair of some sort of a normal divorce. This data may begin to tell us something about the similarities between fictional relationships and real-life relationships of the people writing the show as well as those viewing it. This is a promising starting point for further research on how the portrayal of romantic relationships in the media could potentially influence viewers. Since my text corpus is smaller than I would have liked, I think it would be interesting to compare different TV shows of the same genre for the themes common in romantic relationships. Yet, even querying a corpus of around 850,000 words yielded interesting results that can inspire further research. Potentially stemming to film franchises or other tv shows of high popularity. I am curious to see how these results would change or stay the same across shows from different eras or periods in time. Adding more texts to my corpus within a larger time frame would be helpful especially as relationships move to a more digital frontier through dating applications and fewer social interactions caused by the Covid-19 pandemic. It still makes me wonder though, would the themes I found from friends remain true even today?
Works Cited (MLA)
Galician, Mary-Lou. Sex, love, and romance in the mass media: Analysis and criticism of unrealistic portrayals and their influence. Routledge, 2004.
Hefner, Veronica, and Barbara J. Wilson. “From love at first sight to soul mate: The influence of romantic ideals in popular films on young people’s beliefs about relationships.” Communication Monographs 80.2 (2013): 150-175.