Ever get an email that is a little suspicious? Perhaps it is from an unknown sender, contains a file, or is just about a strange topic. Well, I have and I found the email in my Junk folder. I got to thinking how my email recognized the message as a spam and I suspect that a great deal of what deems an email as fraudulent has to do a great deal with the language it is written.
Introduction
For this assignment, I will analyze a corpus I found on Kaggle created by Rachael Tatman. The corpus is a text file consisting of over 4,000 Nigerian fraudulent emails(2,241,651 words) from 1998 to 2007. So what is a Nigerian fraudulent letter? According to the FBI, “Nigerian letter frauds combine the threat of impersonation fraud with a variation of an advance fee scheme in which a letter mailed, or e-mailed, from Nigeria offers the recipient the ‘opportunity’ to share in a percentage of millions of dollars that the author—a self-proclaimed government official—is trying to transfer illegally out of Nigeria.” For example:
Dear Sir,
I am Barrister Tunde Dosumu (SAN) solicitor at law. I am the personal attorney to Mr. Eton Simon, a national of your country, who used to work with Shell Petroleum Development Company (SPDC)here in Nigeria. Here in after shall be referred to me as my client. On the 21st of April 2000, my client, his wife And their three children were involved in a car accident along Sagbama Express Road. All occupants of the vehicle unfortunately lost there lives. Since then I have made several enquiries to your embassy to locate any of my clients extended relatives this has also proved unsuccessful.
After these several unsuccessful attempts, I decided to track his last name over the Internet, to locate any member of his family hence I contacted you. I have contacted you to assist in repatrating the money and property left behind by my client before they get confisicated or declared unserviceable by the bank where this huge deposits were lodged, particularly, the CITI TRUST BANK where the deceased had an account valued at about US$14.7million dollars . The bank has issued me a notice to provide the next of kin or have the account confisicated within the next ten official
working days.Since I have been unsuccesfull in locating the the relatives for over 2 years now I seek your consent to present you as the next of kin of the deceased since
you have the same last name so that the proceeds of this account valued at US$14.7 million dollars can be paid to you and then you and me can share the money. I have all necessary legal documents that can be used to back up any claim we may make.All I require is your honest co-operation to enable us see this dealthrough. I guarantee that this will be executed under legitimate arrangement that will protect you from any breach of the law.Please get in touch with me via my private email address of barrister_tunde@lawyer.com to enable us discuss further. Or, call me on 234-80-33-432-485
Best regards,
Barrister Tunde Dosumu (SAN).
Everyone want to avoid fraudulent emails. However, we rely on the software given to us to help deter spam mail. I wanted to understand how machine intelligence identified these letters. I will use word2vec to understand what language indicates a fraudulent Nigerian email.
Training My Model
Creating a Vector Space Model
There are 4 parameters in word2vec used in training a model: ‘vectors’, ‘window’, ‘iter’, and ‘negative_samples’. Firstly, ‘vectors’ controls the dimensionality of the model. I kept the parameter at 100 to make my model more precise. Secondly, the ‘window’ parameter allows me to control the number of surrounding words are to be considered contextually relevant. After reviewing a few emails in the corpus, I decided to set the parameter to 10 since lengthy emails lead me to infer that context is gradually laid out. Thirdly, the ‘iter’ parameter controls how many times the corpus is read when training the model. Since my corpus is relatively smaller than other corpora, it would be beneficial to increase ‘inter’ to 15. Finally, the ‘negative_samples’ controls the number of negative samples, or non-context terms, in my corpus each iteration. Therefore, for the size of my corpus, ‘negative_samples’ should be within 5 and 20. So I set the parameter to 15.
Visualizing the Model
Next we need to visualize our model. In a 2-Dimensional plot, the following image depicts clumps of words that signify words that appear in the corpus that have the same meaning. This will help me ask more specific queries later in training my model.
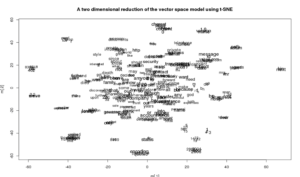
I think it is most notable to identify “necessary” and “documents” overlap one another where m[1] = -20 and m[2] = 40.
Common Clusters
Next we need to list out the clusters we see in out plot. The plot above is quite messy and illegible in certain clumps. So listing out 10 clusters and the relating 15 words would help us create more queries for out model.


Now which groups are significant? Well to answer that question, we need to look at how the corpus is formatted. Thanks to Rachael Tatum, the emails are formatted with meta data-like information to help present information about the receiver and sender. Now it is a better of separating the meta data from the email contents.
- Cluster 1 seems to relate to possibly the meta data. “www.tiscali.co.uk” is an email carrier, which I picture to be the UK-equivalent to America’s Microsoft Outlook.
- Cluster 2 looks to relate to the email content.
- Cluster 3 has a religious context which I imagine persuades the email receiver to better trust the sender’s content.
- Cluster 4 aligns with the email content, more specifically, the impersonation of the email sender. Remember that Nigerian letters involve the impersonation of high ranking officials.
- Cluster 5 are words that lead me to infer they relate to raising the importance of the matter.
- Cluster 6 depicts locations and settings within Africa. “department”, “burkina” “faso”, and “cotonou” describe either an infrastructure-related sector or a geographic location.
- Cluster 7 and Cluster 8 clearly must be contents of the meta data as they are describing the context headers created by Rachael Tatum.
- Cluster 9 refers to time so this can be applicable to both the meta information and the email content/
- Cluster 10 portrays a financial transaction, which alludes to the monetary exchange caused by Nigerian fraud letters.
Specific Queries
Now we get to fine tune the model as a whole by looking for terms that are closest to a given words or phrase. The queries I ran ca be categorized into 2 categories. The first being words one would think relates to email fraud and second being queries thought up from the above clusters.
For the first set of queries, I ran closest_to(~”cover” + “up”, 20). I initially associated “cover up” with email fraud and found the associating terms that all have common definitions relating to money.
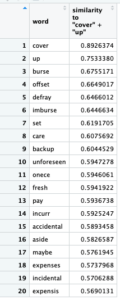
The results lead me to believe fraudulent emails portray a con-like operation to lure the receivers of these emails.
I also searched closest_to(“fee”, 10). Usually, monetary scams are those related to making you feel obligated to transfer money to a cause. However the relating words to ‘fee’ consisted of ‘mobilization’, ‘fees’, ‘consignment’, and ‘setting’. All of which have less than a 0.65 similarity to ‘fee’. Therefore, I predict that some pleads to pay a fee are intended to enact trust so that the email’s sender can take charge of a reader’s possession.
The next query I searched is closest_to(“please”, 10) to identify terms that appeal to the reader.
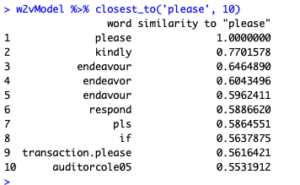
The output, I found, to be quite interesting. Almost all the similar terms are what I suspected. I inferred that fraudulent emails try to sway the reader’s sympathy using kind pleads.
Next I moved on to queries I developed while creating my model.
First I ran closest_to(‘god’, 10) because I did not suspect religious appeals from the receiver.
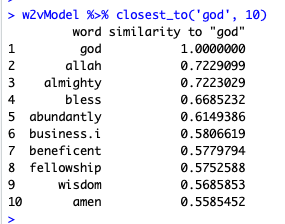
I was not surprised to see ‘allah’, ‘almighty’, and ‘bless’, but I am curious as to how ‘beneficent’ occurred more frequently than ‘amen’. Nevertheless, the results confirm that the source of fraudulent emails use appeals to religion to persuade the receiver to make a monetary payment.
Secondly, I ran closest_to(~”secret” – “audit”, 15) and got:
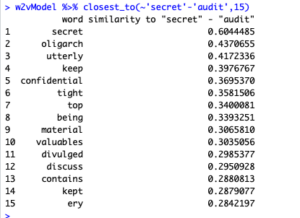
“oligarch”, and “utterly” are surprising to me. An “oligarch” is a ruler of an oligarchy, a government form in which the power rests in a small group of individuals, and “utterly” is defined as an extreme. These results lead me to believe that some contexts of monetary transfers are promised to be secure and overseen by a limited number of people.
The third query I searched is closest_to(~”help” – “donate” + “pay”, 20) with the intention of asking “donate is to help as pay is to ..”
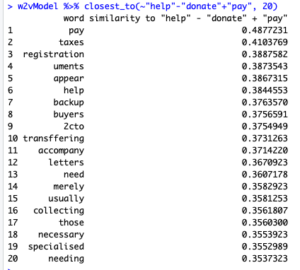
And we can see that “pay is to taxes” So I can conclude that some fraudulent emails are asking favorably for money to help a cause, whereas others make the reader feel obligated to pay a fee.
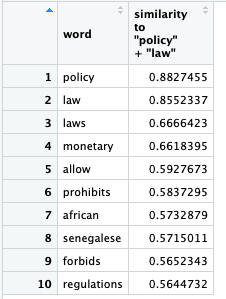
This led me to ask another query: closest_to(~”policy” + “law”, 10) where I concluded that some emails may urge the reader to may a payment to fulfill a fee caused by a violation of a certain policy or law.
Conclusion
Now that we have a trained model, let’s revisit out research question: what language indicates a fraudulent Nigerian email. By using word2vec on my relatively small corpus, I am able to curate possible scenarios that indicate a fraudulent email. Some being that you are obligated to pay a fee, make a donation to a fake business, or having trusted group manage your assets. The language used in fraudulent Nigerian emails are not too different from the average fraudulent letter. The only major difference is that Nigerian letters are sourced in helping highly ranked individuals in Africa. These are characteristics can be identified with further research into investigating why Nigeria is known as a prominent source of emails. Paralleled to other studies of language in fraudulent letters, these letters are curated such that the language creates a sense of urgency, security, or assistance and generosity. All of which are still based on malicious motives by preying on recipients’ moral obligations.
References
Radev, D. (2008), CLAIR collection of fraud email, ACL Data and Code Repository, ADCR2008T001, http://aclweb.org/aclwiki
https://www.fbi.gov/scams-and-safety/common-scams-and-crimes/nigerian-letter-or-419-fraud