Introduction
There is loads of information on the internet and we are a generation that has grown up with this vast resource at our fingertips. So much information all at once however is overwhelming. No single person can comb through every post on the internet and neither should they be able to as that is a highly inefficient information gathering method. Now more than ever we rely on categories and metadata tags to sort through to the information we need when we need it. But who decides what information is relevant and what categories the information fits in? For the Word2Vec Project, I identified BBC News as my corpus, loaded cleaned text files into R studio, used the programming language R to train my model, and then conducted analysis with the trained model in the word2vec package. This process was used to explore the research question:
“What is the influence of way in which metadata tags are defined and what specifically is its affect in relation to gender and sexuality?”
Corpra
I originally planned to use New York Times articles from The New York Times Article Archive where I would be compare articles where the perpetrator of the crime is white to articles where the perpetrator is a person of color to explore the question of racism in the media. I wanted to query in cluster sizes of ten.
Closest to:
- “white”-“crime”
- “poc”-“crime
- “criminal” + “white”
- “criminal” + “black”
- “criminal” + “asian”
- “criminal” + “native american”
- “criminal” + “hispanic”
However, the Copyright rules for reproducing New York Times articles are strict so I changed my corpus to a HuffPost News Dataset from Kaggle and prepared to search similar queries. Still, I ran into another issue. The text needed cleaning because of the way quotation marks converted and the corpus was too large for the R Studio server and kept crashing it. Thus, I had to choose another new corpus: BBC News is a reputable British news channel that covers international news as well as news from the UK, United States, and Canada. The queries about race and crime did not run well on this corpus so I switched my research question and decided to query the following in clusters of ten.
Closest to:
- “same + sex”
- “woman”
- “man”
With a corpus as large as BBC News, the amount of data had to be cut down for the purpose of utility. This particular dataset is from 2004-2005 and has five hundred and ten business news articles, three hundred eighty six entertainment articles, four hundred and seventeen political news articles, five hundred and eleven sport articles, and four hundred and one articles about technology. For each article, a summary is provided in the Summaries folder. This information while perhaps impressive, is not very useful.
Rephrased, the same information is much easier in use for calculating total word count. In the News Articles folder there are 2225 articles divided between the categories of: business, entertainment, politics, sport, and technology. The 5 categories in articles and 5 categories in summaries each category with around 400 articles brings the article count to 4,000. The articles and summaries are approximately 400 words. This makes the total word count around 1,600,000 which is just over a million and satisfies the word count requirement of 80,000. Already we can see an example that categories makes information processing easier.
I trained my model separately on each of the five categories of business, entertainment, politics, sport, and technology so that comparisons could be made between the categories on how the articles were tagged.
Results
Results indicated that words related to man, woman and same-sex were grouped with differently for each category. On the other hand across all categories LGBT, queer, and trans yielded no results across all categories.
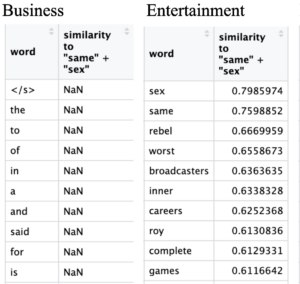
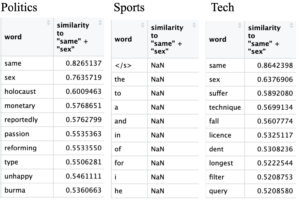
Figure 1: Query word closest to “same + sex”.
I found it interesting that across the board LGBT, queer, and trans yielded no results and while querying the token “same + sex” found more success, there are still no results in business or sports. In entertainment querying “same + sex” found words like ‘rebel’, ‘worst’, ‘inner’, ‘careers’, and ‘games’. While querying in politics brought up ‘holocaust’, ‘passion’, ‘reforming’, ‘type’, and ‘unhappy’. Querying in technology received results like ‘suffer’, ‘technique’, and ‘licence’.
What first made me say, “Huh! That’s weird” was that querying “same + sex” in business yielded nothing. Due to the recent rise of LGBT+ in mainstream media, targeted advertising using rainbows has become popular, so I wondered why there was no talk about that.While it makes sense that there was not much overlap between same sex and sports as being gay has no impact on how good of a sports player someone is, I had still expected some. However when remembering that the articles are from 2004 it is clearer why that is the case. Stars like Megan Rapinoe and other gay sports champions may not have felt safe coming out at such a time and even if they did would the news cover it or label it as sports news? In entertainment it seems that there was some rebelling from social norms with LGBT games, making gaming ahead of its time and perhaps some career opportunity. In politics “same + sex” brings up the holocaust perhaps because gays like jews were targeted and killed during the holocaust. Reforming suggests that being gay at the time was seen politically as something wrong that needed to be corrected. While technology talks about techniques and licences maybe in terms of conversion therapy or the such.
After doing some research, it turns out that in the United States in 2003, the Lawrence v. Texas Supreme Court Decision was just passed criminalizing and declaring gay sex to be unconstitutional. It was only recently, in 2015, that the Obergefell v. Hodges Supreme Court Decision granted the right to marry to same-sex couples in all states by the Due Process Clause and the Equal Protection Clause of the Fourteenth Amendment of the U.S. Constitution (Our Family Coalition). However it is also important to remember that the United States is not the only country in the world. In 1967 the Sexual Offences Act, an Act of Parliament, legalized homosexuality in the UK between consenting men 21 years or older (The British Library). Thus during 2004-2005 period where the corpus is from, it makes sense that while there was some publication on same sex relationships but that it was sad and bad.
Overall the words associated with “same + sex” have very negative connotations in the cases of ‘worst’, ‘suffer’, and ‘unhappy’. Although this does not mean that there was no positive coverage of LGBT issues at the time, the more I look at the data I find it unlikely that there was.
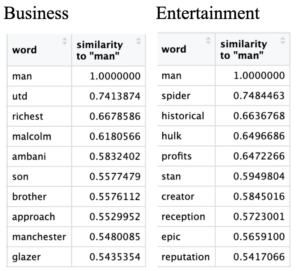
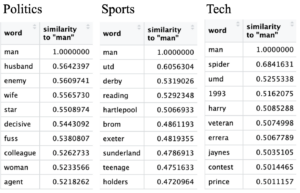
Figure 2: Query word closest to “man”.
Much to no one’s surprise querying words close to “man” received nice words like ‘richest’ in business, ‘epic’ and ‘creator’ in entertainment, ‘husband’ and ‘colleague’ in politics, and ‘teenage’ and ‘veteran’ in the sports and technology categories. Straight men are the most privileged sexuality and gender group, thus media portrays them as heroes in the cases of ‘spider’ man and ‘hulk’ as well as having ‘repulation’ and being the ‘star’ of the show. It is interesting that “man” also comes with ‘richest’. This adds another layer of privilege associated with the male gender: class.
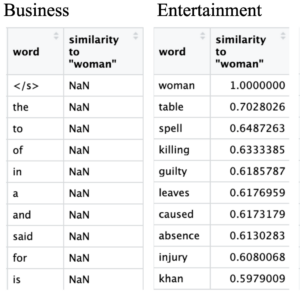
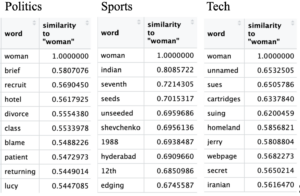
Figure 3: Query word closest to “woman”.
Querying “woman” in business yielded shockingly no results. I thought women had been in the workforce long enough for there to be news about women in business. Apparently not. Sexism is still at large. In entertainment women are villainized by words like ‘killing’, ‘guilty’, ’caused’, ‘injury’, and ‘absence’. Although the witch hunts are long over the female gender is still associated with ‘spells’ or witches. The entertainment industry as of 2004 and 2005 seem to have a target audience of men. All this blame towards women in the entertainment industry is especially worrying because women are also sexualized by that same industry, causing an intersection of blame, violence, and sex. Perhaps that is one of the many contributing reasons to the prevalence of sexual violence towards women. In politics querying women brings up ‘recruit’, ‘hotel’, ‘divorce’, ‘brief’, and ‘blame’. This also leads to a negative portrayal as ‘recruit’, ‘hotel’, ‘divorce’, ‘brief’, and ‘blame’ paint an unprofessional image. It also shows that women’s personal affairs and lives are more scrutinized than that of men. For sports I am unsure why ‘seed’ comes up so often in relation to “woman”. For the most part querying “woman” in technology leads to ‘sue’ and ‘sues’. I’m not entirely sure why this is either. These two categories could warrant further exploration.
Conclusion
What initially struck my interest in exploring the question of the effect of metadata tagging and how that is defined and who is defining it relates to a conversation we had in class. Someone brought up that many countries had documented use of vaccines before Europeans, but if this data was tagged as ‘primitive behavior’ opposed to ‘discovery’ or ‘vaccine’, then this could lead to encouraging the false view of European superiority. Another issue I care deeply about is the intersection of gender sexuality and discrimination. Because of who I am I’ve had to think about these issues more often and deeply than your average straight man. Thus, this topic has also been included in the research question and explored.
During this project what really surprised me the most was that I forgot that same-sex marriage in the United states had only been legalized in 2015 and only very recently started to gain mainstream approval. Despite being saddened by the words used to describe same sex couples in 2004. It’s exciting to see how far the LGBT+ movement has come. While it is easy to become used to the way things are, we should also not forget the past and look at the big picture.
Overall the project shows that in BBC News in 2004-2005 the LGBT and women were portrayed negatively to neutral or not at all while men were portrayed positively. We already knew that, but the project also yields some explanations and nuances.
Extrapolating the research question of tagging and definition to today’s news, some questions that come up are: Does information about COVID fall under the political, business, or technology category? Does it deserve its own category? How would the tagging of the category influence how this information is processed?
Works Cited
Our Family Coalition. “LGBTQ Rights Timeline in American History.” Teaching LGBTQ History, Our Family Coalition and ONE Archives Foundation, 2017, www.lgbtqhistory.org/lgbt-rights-timeline-in-american-history/.
The British Library. “A Timeline of LGBT Communities in the UK.” The British Library, The British Library, 6 May 2014, www.bl.uk/lgbtq-histories/lgbtq-timeline.