Introduction
University Inc.
I wish I could be clever enough to coin the term but, instead, it appeared in a 2015 article published by The New York Times[1]. In it, author Fredrik deBoer describes his experience as a graduate student at Purdue University. He comments on the multi million dollar renovations that have occurred around campus and states that “this orderliness [caused by the renovations] is just a secondary symptom of a more pernicious trend: the creeping corporatism of the American university”. The belief that universities are a business first and foremost shouldn’t come as a shock. As tuition increases, universities constantly try to make improvements. It is in the university’s best interest to portray a unique identity that prospective students can find no where else. However, the obvious question follows:
Is the uniqueness of a university’s identity truly unique?
Background
An article, entitled “An analytical model for university identity and reputation strategy work”, was published by researchers from the University of Gävle in July 2015[2]. In it, the concept of a university’s identity is “constructed by four dimensions: organizational identity, symbolic identity, image, and reputation”. Organizational identity is defined as being “part of the strategic process” and that is based on public relations, i.e. being “dependent on aesthetical impressions and feelings”. Because of this, organizational identity is closely tied with managerial decisions. Unlike organizational identity, symbolic identity is less abstract. Symbolic identity is improved when a university creates symbols that “serve as important vehicles for identification, motivation and culture within the organization”. This occurs in situations such as when university buildings are modernized or product designs are improved. The last two items that define a university’s identity are similar but have a key difference. While both image and reputation are “founded on impressions and attitudes toward the organization” by the outside community, image is based on short-term perception, whereas reputation relies on long-term perception.
For the purposes of this project, I will only use organizational identity and symbolic identity. Because I am using information from a university’s student body, it would be difficult to get an outside perception of the school.
Methodology
In order to determine if identities are truly unique, I will be using data from social media to create several corpora, each relating to a unique university, followed by word vector analysis. The usage of social media when researching social interactions and public opinion is not uncommon. Sites such as Twitter and Facebook provide millions of data points that can be used prove a hypothesis. However, a problem arises when more than one social media platform is used. The style and content of Twitter data is vastly different than that of Facebook in terms of word count, anonymity, demographics, etc. In order to account for these differences, the data needs to be normalized in some manner. Otherwise, the results may not accurately reflect the population. Even with the added difficulty, I decided to use data from Twitter and Reddit.
Twitter has millions of users and, more importantly, millions of Tweets. In addition, the style of each Tweet is consistent. While the content may vary, each tweet is limited to 280 characters and, due to the nature of Twitter, the tone of each Tweet is relatively informal. This last point is critical to this analysis, as I am trying to see how the student body feels about a school. The last thing I want is to be comparing text that is from an academic source. There is also the benefit of the relative lack of anonymity. It is very each to filter out tweets from universities, and just focus on individuals. With all of these advantages, I considered just using Twitter data. However, Twitter data has many limitations, which are detrimental to this project. First, based on the character limit, in order to get a hypothetical corpus size of a million words, over ten-thousand tweets would need to be collected. There is also the issue of Twitter’s developer toolkit. For the most part, Twitter does a wonderful job of making its data accessible. However, it is only possible to collect Tweets from the last seven days without purchasing a premium option. This combination significantly limits the amount of text that can be gathered from the student body of a specific school.
Compared to Twitter, Reddit is often thought to be a smaller or less familiar social media site. However, as of 2017, both sites have roughly 330 million active users[3]. That being said, because Reddit has subreddits, the number of members that have a similar interest is much smaller. Unlike Twitter where a hashtag might have five different meanings to five different people, subreddits are dedicated to one specific topic. This makes it ideal for this project. By looking at a subreddit of a specific university, I can guarantee that the collected text is only about that university. In addition, the anonymity allowed by Reddit, combined with the lack of a word count, allows for very in-depth discussion.
Natural language processing, otherwise known as NLP, is a branch of computer science that focuses on enabling computers to understand human language. One small facet of NLP are word vectors. In a very basic sense, word vectors represent a meaning of a word with a vector of numbers. Each number corresponds to some aspect of the word’s meaning. This is helpful when trying to determine if two words are similar. For instance, consider the words king and queen. Both words might have a point that would correspond to power but queen might also have a point that relates to femininity. This ability to break down words into just numbers is advantageous because it allows for the ability to add or subtract vectors, which is useful when trying to create analogies. In order for these relationships to be accurate and useful, the size of the initial text corpus should be greater than ten million words. For the sake of this project, results can be drawn from text corpora of around one million words. However, it is worth noting that, due to the limited size, the results may not be reflective of the entire population.
Because I am trying to determine whether individual universities have individual identities, each corpus needs to contain text from only one school. Unfortunately, this limits the word count but it allows for results to be drawn that are relevant to the research question. Initially, I had hoped to have the same amount of text from Twitter and from Reddit in each corpus. Unfortunately, this was very difficult to accomplish. The biggest problem was that the Twitter API limited data collection to the past 7 days. Because of this limitation, I was only able to retrieve, on average, about 200,000 words for each university.
In order to limit the effect of this on my research, I randomly selected five universities from the top 100 universities based on enrollment[4]. If one university did not have enough Twitter or Reddit data, I removed it from the list and selected five new universities. I repeated the process until I was able to find five universities with enough data.
| School | Referenced in this post as | Size of Reddit data (in words) | Size of Twitter data (in words) | Total size |
| Arizona State University | ASU | 1294598 | 191662 | 1486260 |
| Florida State University | FSU | 719182 | 212592 | 931774 |
| Harvard University | Harvard | 447765 | 642063 | 1089828 |
| Ohio State University | OSU | 2635174 | 352615 | 2987789 |
| University of California, Los Angeles | UCLA | 1750263 | 279530 | 2029793 |
As evident by the number of words from Reddit and the number of words from Twitter, it was very difficult to locate universities that had roughly the same amount of data from each source.
Once the five schools were chosen, I used the Pushshift API to retrieve reddit comments and the rtweet package to retrieve twitter comments. I did not feel that there was a need to clean the Reddit data but I did remove urls, hashtags, and users from the Twitter data as it was a lot more prevalent. Once the data was cleaned and filtered, I used the wordVectors package created by Ben Schmidt.
Analysis
Based on the background readings, as well as the demographics of both Reddit and Twitter, I decided that it would beneficial to decide on a group of words that correspond the the concept of identity. This introduced some bias into the process, as I was deciding on what words were important, but I feel as though this cannot be avoided. After several iterations of trial and error[a], I decided to analyze the following words:
“social”,”diversity”,”culture”,”campus”,”professor”,”administration”, and, of course, “identity”.
The most valuable tool available in the word2Vec package is the closest_to() function. To put it simply, this function returns a given number of words that are similar to a given word. It also allows for analogies. For instance, if I wanted to find words that were similar to ‘culture’ and ‘diversity’ but not similar to ‘student’, I could provide ~”culture”+”diversity”-”student” as an argument.
ASUHarvardFSU
| closest_to(asu,~”diversity”+”culture”,20) | closest_to(harvard,~”diversity”+”culture”,20) | closest_to(fsu,~”diversity”+”culture”,20) |
| diversity | diversity | diversity |
| culture | culture | culture |
| leadership | ethnic | elements |
| asian | justifying | cultures |
| relations | racial | venues |
| evolution | discourse | reputation |
| multicultural | race | functions |
| inclusion | society | inclusion |
| theatre | statements | snake |
| psychology | 1964 | toxic |
| theories | criticism | european |
| origins | norms | business |
| multimedia | purity | economy |
| engagement | beliefs | centered |
| history | causal | physiology |
| innovators | practices | ifc |
| cultural | segregation | partisan |
| economic | societal | innovative |
| educators | tension | preeminent |
| strategic | stance | music |
When finding similar terms to “culture” and “diversity”, it is interesting to compare FSU to other universities such as Harvard and ASU. While Harvard and ASU contain many terms often associated with diversity, such as “multicultural”,”stance”,”race”, “beliefs”, and “norm”, FSU only contains “inclusion”. This sort of makes sense as only 1.5% of the student body of FSU are international students and 63% are Caucasian[5].
| OSU | UCLA |
| closest_to(osu,~”campus”+”cultural”,20) | closest_to(ucla,~”campus”+”cultural”,20) |
| cultural | cultural |
| campus | campus |
| global | outings |
| community | campusn |
| inclusion | affluent |
| migration | revolve |
| aquatic | condos |
| district | eateries |
| building | based |
| city | themes |
| gardens | cafes |
| agriculture | grassy |
| european | club |
| rehabilitation | ethnicities |
| manufacturing | minorities |
| facility | distraction |
| mart | centered |
| compost | culture |
| promotes | museums |
| diaspora | hilgard |
I was surprised by this data because I had expected more school or city specific locations. Instead, this search term returned general terms, such as “community”,”building”, “cafes”, and “club”. More surprising was that this trend was consistent among the five corpora.
| Harvard | OSU |
| closest_to(harvard,~”identity”+”student”,20) | closest_to(osu,~”identity”+”student”,20) |
| identity | identity |
| student | student |
| body | governments |
| apathy | sitesn |
| composition | organ |
| injustice | vpn |
| politics | organization |
| student’s | disability |
| societal | parent’s |
| viewpoint | identification |
| touring | social |
| barred | slds |
| perks | provider |
| meritocracy | assistant |
| association | literacy |
| failings | diversity |
| selects | quotas |
| advancement | multicultural |
| government | services |
| limiting | employee |
It is interesting that the Harvard corpus contains more words pertaining to more abstract notions, such as “advancement”,”viewpoint”,”injustice” and “apathy”, compared with words like “organization”,”services”,”employee”, “quotas”, and “governments” that are found in the OSU corpus. This data, combined with the previous data sets, suggest that Harvard students are more willing to talk about big picture concepts compared with other schools.
| UCLA | OSU |
| closest_to(ucla,~”administration”,20) | closest_to(osu,~”administration”,20) |
| administration | administration |
| officials | government |
| strikers | department |
| gop | constitution |
| police | university |
| disturbance | dept |
| policy | premise |
| admin | underpaid |
| administrators | bloated |
| backlash | coaching |
| arguments | bureaucracy |
| causing | program |
| boycott | faculty |
| branding | overcrowded |
| enemy | industry |
| protesters | institutional |
| unfairly | staff |
| proposals | ocio |
| anger | investigation |
| negligence | dean |
I did not find it that surprising that university administration is despised by all of the universities in my corpora. However, it is interesting to see the specific language of each university. For instance, UCLA students use “disturbance”, negligence”, and “enemy”, whereas OSU students use “overcrowded” and “underpaid”. Since identities are typically created by the administration, this data might suggest that students are unhappy with the concept of university identity
I’ve included some other tables and graphs in the appendix.
Conclusion
Suppose five people are gathered in a room and you were asked to group them based on similarities, but were not told how to do so. You might group them by gender, or by height, or, if you were feeling particularly lazy, you might consider all five people to be one group because they are all human. There is no way to know ahead of time how you will choose to do so. This research project proposed the same type of question. At the beginning, I expressed a common sentiment that the highest priority of a university is to make money and, in order to do so, the university must portray an identity. Then, I asked whether this identity is unique. When I originally posed the question, I was unsure of the answer. Now, at the end, I’m still unsure of the answer. Hypothetically, if identity just depended on culture, such as campus life, this analysis would show that all schools are the same and it doesn’t matter where a student attends. On the other hand, if identity just depended on diversity, this analysis would show that some schools are more diverse than others. However, the concept of identity is not distinctly defined. Instead, it depends on a variety of factors. While some aspects of an identity may be consistent among all universities, all aspects are not consistent. Based on this research, the unique identities of universities are only, at best, partly unique.
Sources
1. Boer, Fredrik De. “Why We Should Fear University, Inc.” The New York Times, The New York Times, 9 Sept. 2015, www.nytimes.com/2015/09/13/magazine/why-we-should-fear-university-inc.html?module=inline.
2. Steiner, L., Sundström, A.C. & Sammalisto, K. High Educ (2013) 65: 401. https://doi.org/10.1007/s10734-012-9552-1
3. This number appeared on several sites, such as socialmediatoday.com
4. Using data from the National Center for Education Statistics
5. Using data from collegedata.com
Appendix
a. Some words that I considered, such as “campus life” or “dorm life”, did not appear in all of the corpora or did not have many similar words, which is why I went with what I did
Some plots
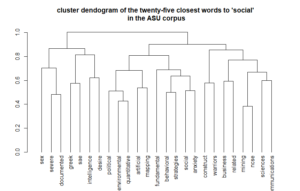
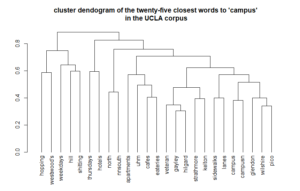
Dendograms show the relationships between words. Nodes closer to the bottom connect words with more similar characteristics.
Above is a plot representing the Harvard corpus. Words that are close together have similar characteristics. These plots are difficult to read which is why they are not included in the actual post. However, they are fun to look at.