Introduction
Movies are deeply indicative of culture and current attitudes, often shaping them and being shaped by them. They can be especially useful in parsing various societal structures or norms, either through criticism of these structures or active participation in them. Of course, a lot can be said through the visual aspects of film—lighting, blocking, and shot composition are all indicative of the gaze of the movie and its perspectives—but the narrative form of the script is at the heart of it. Something film captures very well is dialogue—you can see it actively expressed onscreen, and it serves a variety of functions, from the expositional to the comedic, but the value of dialogue really lies in the dynamics it creates and exposes, the relationships its fleshes out and the insight it gives into the participating characters. Dialogue patterns in film are very much “related to the underlying gender dynamics of each genre… how each genre treats its male and female characters [is a] crucial factor in its use of language” (Kozloff 137). This led me to ask the question:
How does the portrayal of women in film manifest in dialogue exchanges, and what sorts of conclusions might gendered language in dialogue lead us to form about said portrayal?
Methodology
To explore my research question, I needed to use word embedding, a type of word representation that relies on the similarities (or lack thereof) between words, to create a model with the Word2Vec package that positions the words in vector space based on their common contexts or usages. I used the Cornell Movie Dialogs Corpus, a dataset of fictional conversations extracted from 617 movies on IMDb, that is purely dialogue-based. The data was comprised of 304, 713 lines in 220, 579 exchanges, which made it a solid candidate for this project as effective models would need to be trained on upwards of 800,000 words. I had to split up the files due to their sheer size, and used Python to clean up the file, cleaning up spacing, removing the separator characters, the line number, the movie number, character identifying metadata that linked the file to a different file, and dialogue tags that indicated who was speaking, a holdover from the original script formats. This brought the final word count to 3,148,482 words.
Queries
I trained my model with 200 iterations, and the very first thing I tried was clustering the data around 200 centers, selecting 15 random clusters and 10 words from each cluster to view. Using less centers and more selected words from each cluster gave me a lot more character names as clusters as well as more irrelevant clusters.

A notable part of the clusters is the first two words in the first cluster, “sir” and “mister”, which are masculine terms, and the first cluster seems to be centered around positions of authority, specifically the police or the military. The other clusters don’t yield any explicit association with gendered language or gender roles.
Then I ran a search for word commonly associated with/closest to “woman”, with 20 results.
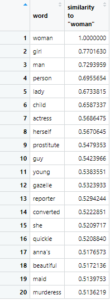
The first few parts of the search were pretty straightforward, but when it got to the latter part of the results, I was particularly intrigued by the results “prostitute”, “young”, “gazelle”, “quickie”, “beautiful”, “maid”, and “murderess”. There seems to be a heavy tie-in to sexuality, youth, desirable naivete, and objectification.
I ran the search again for “man”, again with 20 results.
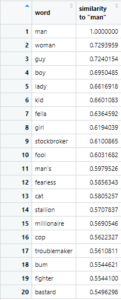
“Stockbroker”, “fearless”, “stallion”, “millionaire”, “cop”, “troublemaker”, “bum”, “fighter”, and “bastard” all seemed to be significantly different than the general energy of the words associated with women. There seems to be a general gearing toward aggression, money, thrill, and power in contrast to the words associated with women.
Then I wondered if I could run a query to make this difference clearer, so I ran a search for the space between the terms “woman” and “man” to see which words were similar to the term “woman” but not “man”.
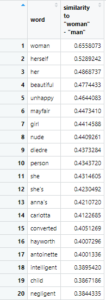
“Beautiful”, “unhappy”, “nude”, “child”, and “negligent” stood out to me in this set—women’s appearance as well as their unhappiness being a focal point in dialogue made sense to me (as well as “nude” and “child”) because many conversations involving them, especially ones that have a lot of conflict in them, can involve appearance, sexuality, fertility, pregnancy or marital strife.
Much of the scholarship I was reading about women in film suggested that women are “overwhelmingly valued in film based on their identification as a mother, wife, or lover” (Murphy 9). I decided to see if this held true for my dataset and ran a query that constructed an analogy essentially asking the question: “woman” is to “lover” as “man” is to what?
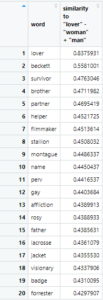
The roles for men seemed to be much more diverse – “brother” and “helper” made sense, as it would indicate a similar level of closeness as a lover, but there was also words like “survivor”, “filmmaker”, “stallion”, “perv”, and “visionary”. There was a much more intense or charged feeling to many of the words (some lacking as much implied softness as the word “lover”). These words also gave a more independent, individual air than “lover”.
Conclusion
In recent years, there has been a general consensus among many watchers of film, especially through a feminist lens, that women’s portrayals in film have fallen short of fully three-dimensional characters, often falling into stereotype, objectification or very restrictive, heteronormative roles. I went in with a general idea of what I was expecting, and indeed found that the dataset I used yielded similar results to those expectations. Traditionally masculine and traditionally feminine characteristics and tropes seemed to loom large in this dataset, particularly the aggressive, confident, or intelligent man and the beautiful (sexualized), loving woman, as well as a focus on family or age for women. I think that dialogue is a great way to find this out because of the commentary that people make on each other and others, and the way it reveals these particular events and characterizations. I originally intended to do this across genres, and train various separate models to compare gendered language in different genres (for instance, science fiction vs. romantic comedies), but the scale of the task was too great considering the amount of movies there were, so I left it as one dataset. The metadata is available in separate files provided with the corpus, but I couldn’t find an effective way to link them together for analysis. In a future version of this project, I would love to run a more extensive comparative version of this, perhaps even comparing other aspects like gendered language in films from the early 20th century early vs. the 21st, or something else having to do with time.
Limitations
The movies that the dataset collects from appear to be in no particular grouping, so this is limited in the insight it can offer because it’s a generalization and perhaps not the best representation that it could be. I would be interested to see how this changes if it were about the most popular movies of a certain year or something of that nature instead—I would expect the conclusion to be more specific and relevant in that case.
Resources
Kozloff, Sarah. Overhearing Film Dialogue. University of California Press, 2000.
Murphy, Jocelyn Nichole. “The Role of Women in Film: Supporting the Men — An Analysis of How Culture Influences the Changing Discourse on Gender Representations in Film.” ScholarWorks @ University of Arkansas, 2015.