A Quick Purpose Statement
I am using Word Vector Analysis to analyze texts from the Library of Southern Literature in order to compare the tonal differences in accounts of black marriages as opposed to accounts of white marriages in both the period before and the period after the Civil War. I will attempt to analyze these differences in the broader context of existing scholarly work on race as it relates to marriage within the South. The rest of this post will focus on my motives, methods, and any significant results.
Briefly On Word Vector Analysis
The purpose of word vector analysis is to combine a corpus, which is collection of related textual documents, in a way that strips individual documents’ unique, overarching meaning in order to focus purely on relationships between different words across the whole. This method groups words that are used in similar contexts together; for example, the word “July” is usually used in the same context as the word “August,” so the algorithm for word vector analysis encodes their similarity as physical proximity on a spatial model. Users can choose to include or exclude relationships between terms: asking a model trained on documents relating to nobility by saying “prince” – “man” or “prince” + “woman” would both return “princess”. The models that this method generates are useful because they enable comparison between different corpora by using the same methods and terms for querying.
Some Initial Motives
When I was looking through the Library of Southern Literature, a collection of literary works digitized by UNC Chapel Hill and hosted by the digital publishing initiative DocSouth, some topics that kept appearing were:
- Relationships between slaves and their masters
- The concept of a plantation as a family unit
- The purity of women, both of color and white
- Antebellum masculinity power dynamics
I felt that the concept of matrimony would be the perfect thing to research through word vector analysis in this corpus because it is at once deeply ingrained in all of these topics and too subtle to pick out individually in each text in my corpus. If I was to do analysis on the topic of marriage in a traditional way, I would have either been forced to focus on texts specifically about marriage or compelled to pore over a huge number of documents in order to pick out individual phrases and paragraphs related to the subject. With word vector analysis, I have a reliable method to not only find terms related to marriage, but also to compare how these related terms change over time, provided I train models with texts from different time periods. Comparing the concept of matrimony over time in this corpus would allow me to utilize this technology to its fullest extent. In addition, using a fiction corpus instead of a non-fiction one enables me to say that my results are subjective; the advantage of this is that with respect to a topic as socially ingrained as marriage, analyzing through a subjective lens would generate results that fit each era’s sentiments and opinions without the analytical bias that would come from my hypotheses on nonfiction data.
Curating The Data
I had great success preparing my corpus for vector analysis using almost exclusively the terminal on my Mac computer. The methods I used were for the most part non-invasive; I rarely had to remove something manually from a text, and the process only required me to skim briefly over relevant parts of my corpus. I started by using the grep command to see if the word “marriage” is referenced in my corpus at all. This is the command I used:
![]()
This means “Return all the lines in the text contained in this folder that contain the word “marriage.”
I was immediately returned about 600 unique lines, and that confirmed to me that I was on the right track.
I next chose three terms manually that were most common in the context of marriage (meaning that it’s rare for these terms to have any other connotation); these were “marriage,” “widow,” and “wedding.” I fed these into a separate grep command with particular flags so that only the filenames of the files without any references to these terms would be listed.I then “piped” the results to a command that would remove those files.
![]()
This means: “Return the names of files in this folder that do not contain the words “marriage,” “widow,” or “wedding,” and remove these files from the folder.
To check that these files were properly removed without damage to any files that I wanted to keep, I did additional grep commands to check that the number of files that did not contain the terms I chose was zero, and the number of files that did contain those terms was greater than zero.
In order to label and encode footnotes in each of their documents, the Library of Southern Literature used brackets extensively – I wanted to remove brackets and bracketed text because when I did a grep command to skim through all the brackets in my corpus, most of them did not contain any information relevant to marriage. I found about three or four instances where the bracketed text was relevant to me and removed the brackets around them manually. Once I was sure that all bracketed text relevant to me was removed from my grep query, I did a sed command to remove the rest of the bracketed text from all txt files in my corpus.
![]()
This means: “Remove in-place all the text that fits this regular expression (for bracketed text) and replace it with nothing.”
After filtering my data in these ways, I used the csv file that came with my corpus when I downloaded it to sort my texts by year and split them into two corpora – before 1865 inclusive, which is the year the Civil War ended, and after 1865. Since there was no data inside the texts themselves that consistently referred to their years of publication, I had to separate them manually by cross-referencing my csv file.
Overall, my collection was big enough that i didn’t have to filter my data extensively in order to get the results I wanted. Removing obvious things like brackets and texts without references to marriage topics turned out to be enough to generate coherent results. I briefly considered removing list formats like 1. 2. etc and a. b. etc. but they were so few and far between, difficult to pick out with regular expressions, and in most cases gave words more semantic information, so I decided against it. I felt that being sparse in my data cleaning methods better exposed words related to marriage because I did not know what relationships would turn out to be relevant – after training my models, I found that words like “hitch,” “courting,” and “plantation” all turned out compelling results when added or removed from “marriage”; over-filtering my corpus would have erased these more subtle relationships.
Results and Analysis
After separately training my two corpora, I began using some of the queries that Ben Schmidt presented with my terms “marriage,” “widow,” and “wedding”. The method that consistently gave interesting results was the “analogy” method that Schmidt referred to. This is the method I mentioned before as including or excluding relationships between terms. I found that I could pinpoint the results I wanted more accurately by using the subtraction sign to find terms in the space between two things than by using the addition sign to find terms closest to two things. “Marriage” + “white” would generate terms related to all marriages plus the ones related to whites, which doesn’t allow me to view white marriages separately from black ones. “Marriage” – “black,” however, ensured that I would only be seeing terms related to marriage and white people.
The first topic I focused on when using the “analogy” method was comparing accounts of marriages between white people before the Civil War to ones after the Civil War. I immediately found that using the word “black” in my queries generated useless and jumbled relationships – I had to replace “black” with “slave” before I got anything coherent. My results for “marriage” – “slave”, which is for the corpus dated to before 1865, is the first image below, and the second is “marriage” – “black” for the corpus dated after 1865.
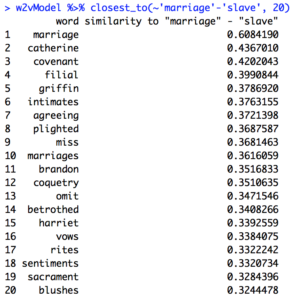
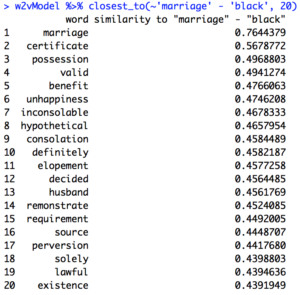
A quick comparison of these terms leads me to the thought that pre-Civil War marriages in the white community were saturated with the concept of courtly love, but marriage was unhappier and less moral after 1865.
To mirror this topic, I used the same method of comparing accounts of marriages before the Civil War and after the Civil war but focused on black marriages. The results for “marriage” – “white” for the corpus before 1865 is the first image, and the same query after 1865 is the second.
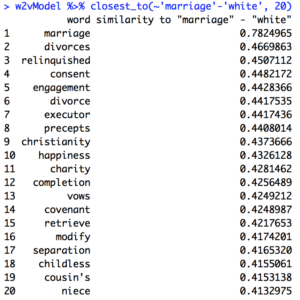
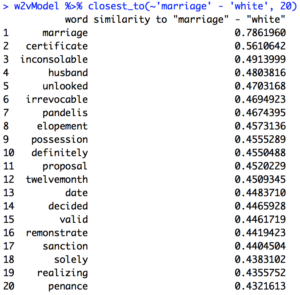
Interestingly, these results are almost identical to the ones before – this led me to think that this type of query was not accurate enough for my purposes.
Out of curiosity, I queried “marriage” – “slave” + “white” and “marriage” – “white” + “slave” to see if anything different would come up – the results returned separated more clearly the differences between marriages between black people and marriage between whites compared to the two sets above. Here are these queries from before 1865:
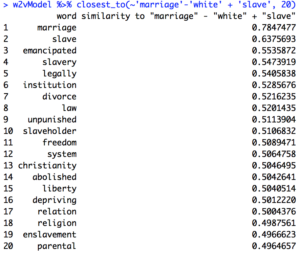
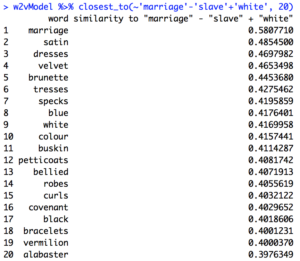
Here are the same sets of queries after 1865:
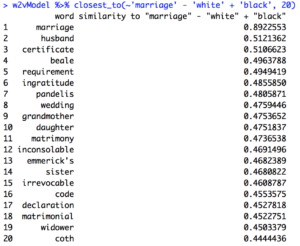
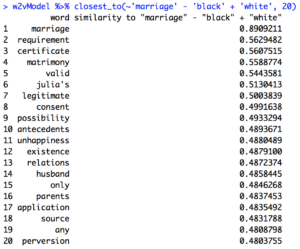
I attempted to do the same queries above where “marriage” was replaced with “widow” or “wedding,” but there were no clearly discernible differences in these results compared to the above results. The terms “widow” and “wedding” turned out only to be helpful in broadening the number of relevant texts to include in my corpora.
The most successful query I compared through the lens of pre vs. post Civil War was “marriage” – “white” + “slave.” The pre-Civil War model returned words like “slaveholder”, “system,” “relation,” “religion,” and most damning, “parental,” which suggest that slave marriage was a way for slave owners to assert a twisted, almost paternalistic authority over their slaves as a tactic to manipulate them emotionally. A control to compare this against is the same query in the post-Civil War model. Here, traditional family terms like “husband,” “grandmother,” “daughter,” and “sister” appear, which suggests that without the manipulative hold of the slave owners, black marriage was restored to having a more traditional structure. It is exciting to have my data be a concrete validation for Patrick W. O’Neil’s hypothesis that,
“…patriarchal ideology held that wives fell under the jurisdiction of their husbands, who were duty-bound to protect and provide for them. In insisting that slave men rule their wives according to the dictates of slaveholders, masters minimized marriage’s capacity to bestow adulthood. Whether married or not, black men would not be patriarchs; instead, they would defer to whites in all matters, including the disposition of their women.” (O’Neil 35)
Future Research
If I had more space, I would have tried to dig deeper into marriage as it relates to religion. The concept of religion, like marriage, snakes through the South in the same way from a Word Vector Analysis standpoint. It would be interesting to compare religion to marriage after doing a similar analysis through a racial lens in order to see any differences in the effectiveness of different types of “analogy” queries. I would also have liked to find whether religious terms were mentioned more in marriages between black people or between white people, and whether blacks and whites followed different religions.
References
“Library of Southern Literature.” Documenting the American South, University of North Carolina at Chapel Hill, docsouth.unc.edu/southlit/.
O’Neil, Patrick W. “Bosses and Broomsticks: Ritual and Authority in Antebellum Slave Weddings.” The Journal of Southern History, vol. 75, no. 1, Feb. 2009, pp. 35.
Schmidt, Ben. “Vector Space Models for the Digital Humanities.” Ben’s Bookworm Blog, 25 Oct. 2015, bookworm.benschmidt.org/posts/2015-10-25-Word-Embeddings.html.